
The vulnerability to be detected for this challenge was an XSS via collision by case transformation due to the misordering of security measures. Solving the challenge does not necessarily require knowledge of the language (Ruby) or the web framework (Roda). Indeed, the problem was more about the concepts of normalization, canonization and Unicode case transformations.
Note: This article is also available in french 🇫🇷. The challenge was announced in this tweet 🐦.
Explanation
The application allows you to search through a list of items and display the corresponding results. The result reflects the value entered by the user and the user controls the GET search parameter, which must be properly sanitized to avoid any security risks. As such, the code performs an escape of dangerous HTML characters (CGI.escapeHTML) and then applies NFKC normalization (unicode_normalize(:nfkc)).
A legitimate use looks like the screenshot below where the user searches for the word ffuf and the corresponding articles are displayed.
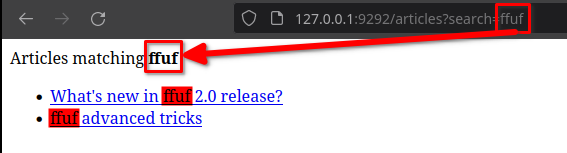
Since the user input is reflected, it is tempting for an attacker to try an XSS payload to attempt to execute JavaScript code in the browser and thus obtain a reflected XSS.
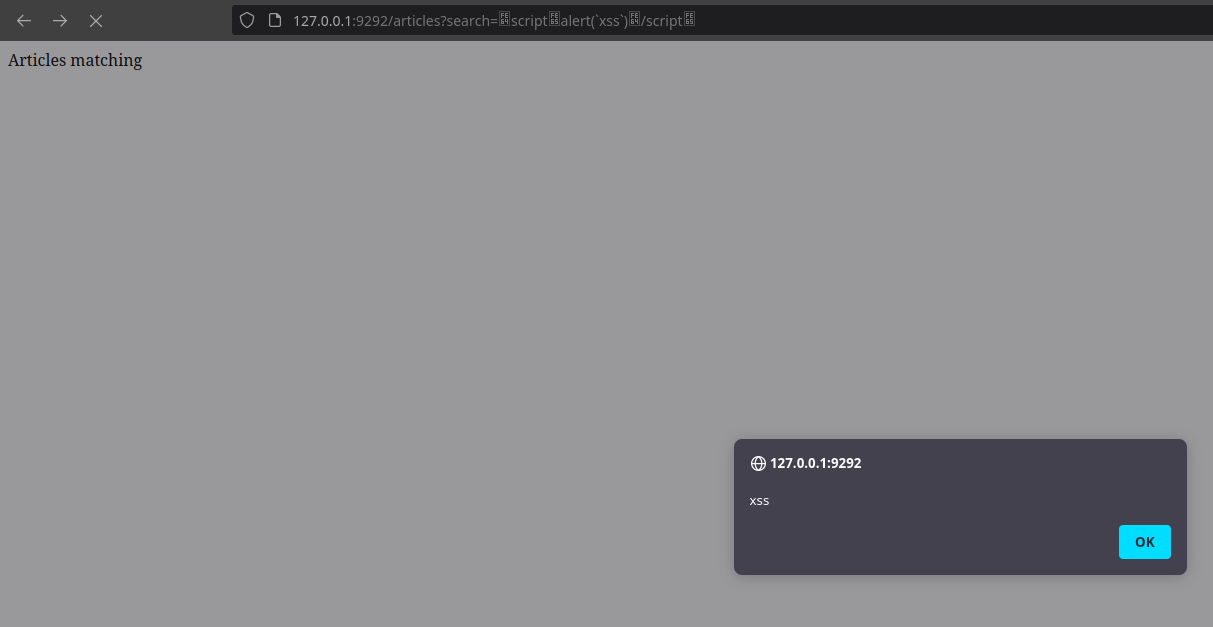
To do this the attacker will use a classic <script>alert("xss")<script> payload. However, this is displayed but not executed thanks to the HTML escape.

The chevrons < and > are escaped in < and >, and the double quote " is escaped in ".

So it does not seem vulnerable at first sight.
However, an additional step is performed on the Unicode string: a NFKC normalization (Normalization Form KC, i.e. a compatible decomposition followed by a canonized composition, see UAX #15).
The compatible decomposition of the characters ﹤ (U+FE64) and ﹥ (U+FE65) is < (U+003C) and > (U+003E). The same is true for < (U+FF1C) and > (U+FF1E). However, these Unicode characters will not be escaped by CGI.escapeHTML because they have no particular role in the HTML standard, only '&"<> are. The NFKC normalization will therefore allow a collision attack (see Unicode attacks – Rump BreizhCTF 2k22). To find characters that will collide with < (U+003C) and > (U+003E) after NFKC normalization, you just have to use the official tools proposed by the Unicode consortium here and there.
To avoid escaping double quotes, it is possible to replace them with /. Indeed, in JavaScript the alert() function will display both a string (usually delimited by ' or ") and a regular expression (delimited by /). Another option is to replace them with a backtick (grave accent, U+0060) which allows you to delimit a string with interpolation but which will not be escaped in HTML. It is also possible to use the same collision technique via normalization with the " character (U+FF02).
The payloads ﹤script﹥alert(/xss/)﹤/script﹥ or <script>alert(xss)</script>

Fixed code
Here is the corrected code:
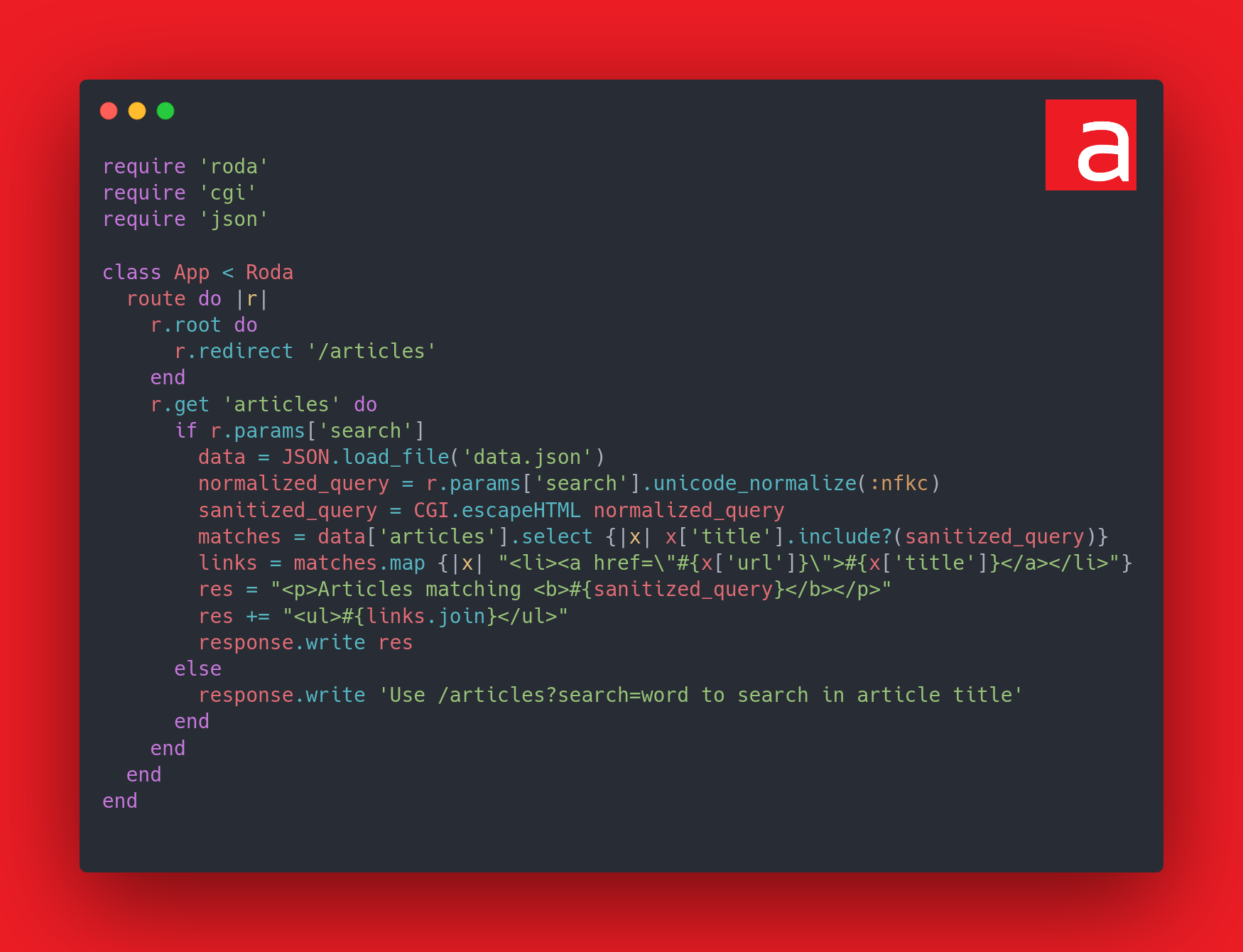
The modified element is the order of safety measures, HTML escape is performed after normalization. Even if a collision occurs, the result will still be escaped.
So the weakness of the code was the incorrect order of security measures (CWE-179).
![]()
The source code is available on the Github repository Acceis/vulnerable-code-snippets.
About the author
Article written by Alexandre ZANNI aka noraj, Penetration Testing Engineer at ACCEIS.