
La vulnérabilité à détecter pour ce challenge était une XSS via collision par transformation de casse due au mauvais ordonnancement des mesures de sécurité. La résolution de challenge ne demande pas nécessairement de connaissance du langage (Ruby) ou du framework web (Roda). En effet, le problème étant plutôt porté sur les concepts de normalisation, de canonisation et des transformations de case Unicode.
Note : Cet article est aussi disponible en anglais 🇬🇧. Le challenge a été annoncé dans ce tweet 🐦.
Explication
L’application permet de chercher parmi une liste d’articles et d’afficher les résultats correspondants. Le résultat réfléchi la valeur saisie par l’utilisateur et l’utilisateur contrôle le paramètre GET search qu’il convient donc d’assainir correctement afin d’éviter tout risque de sécurité. À ce titre, le code effectue un échappement des caractères HTML dangereux (CGI.escapeHTML) puis applique une normalisation NFKC (unicode_normalize(:nfkc)).
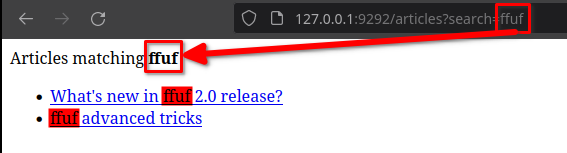
Une utilisation légitime ressemble à la capture d’écran ci-dessous où l’utilisateur cherche le mot ffuf et où les articles correspondants sont affichés.
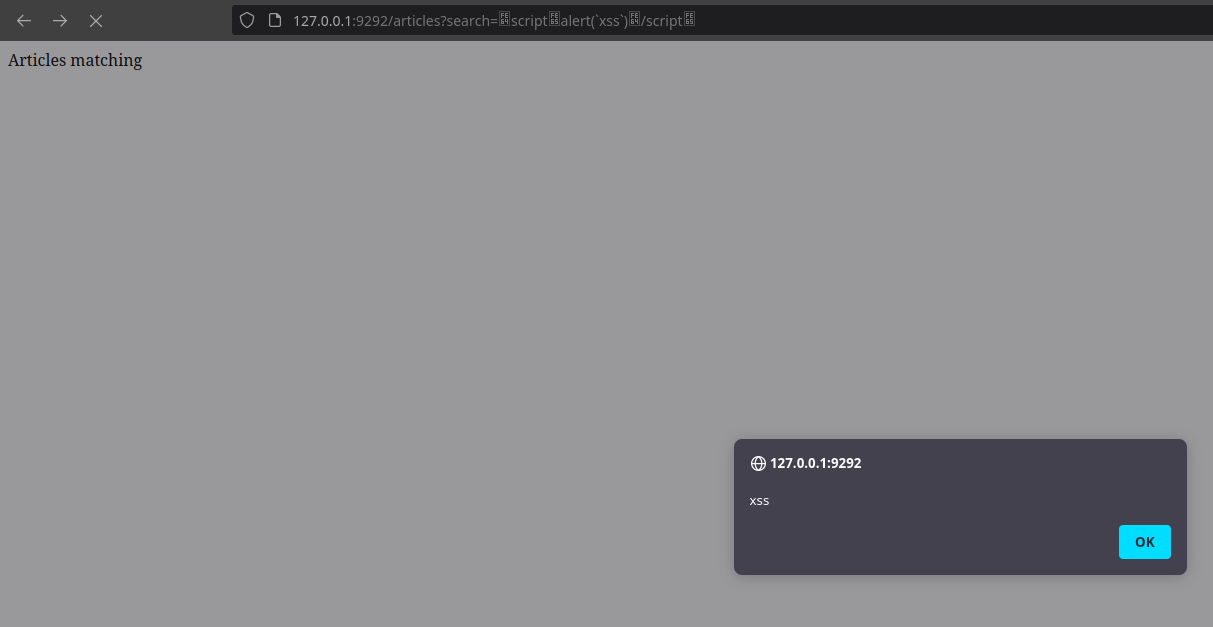
Puisque l’entrée utilisateur est réfléchie, il est tentant pour un attaquant d’essayer une charge utile de XSS pour tenter d’exécuter du code JavaScript dans le navigateur et ainsi obtenir une XSS réfléchie.
Pour cela l’attaquant va utiliser une charge utile classique <script>alert("xss")<script>. Or celle-ci se retrouve affichée, mais n’est pas exécutée grâce à l’échappement HTML.

Les chevrons < et > sont échappés en < et >, et le double guillemet " est échappé en ".

Cela ne semble donc pas vulnérable à première vue.
Cependant, une étape supplémentaire est réalisée sur la chaine de caractère Unicode : une normalisation NFKC (Normalization Form KC, c’est-à-dire une décomposition compatible suivie d’une composition canonisée, voir UAX #15).
La décomposition compatible des caractères ﹤ (U+FE64) et ﹥ (U+FE65) est < (U+003C) et > (U+003E). Il en va de même pour < (U+FF1C) et > (U+FF1E). Or ces caractères Unicode ne seront pas échappés par CGI.escapeHTML car ils n’ont pas de rôle particulier dans la norme HTML, seuls '&"<> le sont. La normalisation NFKC va donc permettre une attaque par collision (voir Attaques Unicode – Rump BreizhCTF 2k22). Pour trouver des caractères qui vont collisionner avec < (U+003C) et > (U+003E) après une normalisation NFKC, il suffit d’utiliser les outils officiels proposés par le consortium Unicode ici et là.
Afin d’éviter l’échappement des doubles guillemets, il est possible de les remplacer par /. En effet, en JavaScript la fonction alert() affichera aussi bien une chaine de caractère (généralement délimitée par ' ou ") qu’une expression régulière (délimitée par /). Une autre option est de les remplacer par un accent grave (U+0060) qui permet de délimiter une chaine de caractère avec interpolation, mais qui ne seront par échappés en HTML. Il est aussi possible d’utiliser la même technique de collision via normalisation avec le caractère " (U+FF02).
Les charges utiles ﹤script﹥alert(/xss/)﹤/script﹥ ou <script>alert(xss)</script>

Code corrigé
Voici donc le code corrigé :
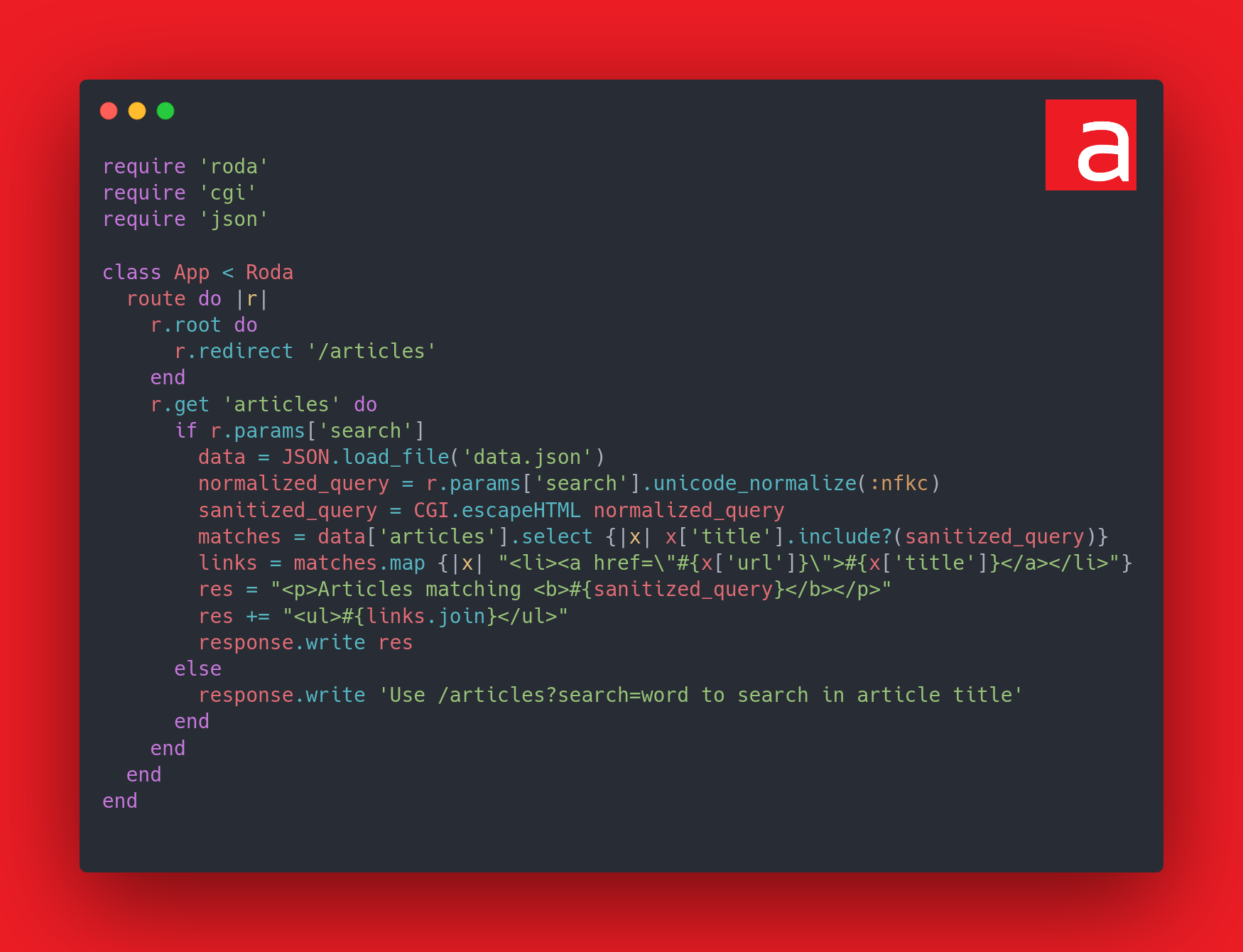
L’élément modifié est l’ordre des mesures de sécurité, l’échappement HTML est effectué après la normalisation. Même si une collision survient, le résultat sera toujours échappé.
La faiblesse du code était donc l’ordre incorrect des mesures de sécurité (CWE-179).
![]()
Le code source est disponible sur le dépôt Github Acceis/vulnerable-code-snippets.
A propos de l’auteur
Article écrit par Alexandre ZANNI alias noraj, Ingénieur en Test d’Intrusion chez ACCEIS.