
n°1 – Open-Redirect – Solutions
La vulnérabilité à détecter pour ce challenge était une redirection arbitraire ("open-redirect"). Au moins trois solutions étaient possibles pour résoudre cette épreuve. La résolution de challenge ne demande pas nécessairement de connaissance du langage (Ruby) ou du framework web (Roda). En effet, le problème étant plutôt porté sur des concepts transverses et l’utilisation des expressions régulières (Regexp).
Parmi les solutions possibles, on retrouve :
- Non-échappement de l’expression régulière
- Début de ligne versus début de chaine de caractère, injection de saut de ligne
- Collision de casse Unicode
Note : Cet article est aussi disponible en anglais 🇬🇧. Le challenge a été annoncé dans ce tweet 🐦.
1 – Non-échappement de l’expression régulière
La partie du code intéressante est la suivante :
@base_url = 'https://www.acceis.fr'
...
elsif /^#{@base_url}\/.*$/i.match?(r.params['redirect_url'])
r.redirect r.params['redirect_url']Le mécanisme d’interpolation de chaine de caractères est assez courant et consiste à évaluer le contenu d’une chaine de caractère pour remplacer des variables par leur valeur, par exemple :
"J'ai #{age} ans."en Rubyprintf("J'ai %d ans.", age);en C$"J'ai {age} ans.";en C#"J'ai $age ans."en PHPprintln!("J'ai {} ans.", age)en Rust
Ici le principe est le même, mais c’est de l’interpolation d’expression régulière, autrement dit le contenu de la variable est inséré dans l’expression régulière, tel quel.
L’expression régulière devient donc :
/^https:\/\/www.acceis.fr\/.*$/iOr dans une expression régulière, le caractère point . remplace n’importe quel autre caractère. On peut donc remplacer le premier point du domaine par n’importe quel autre caractère et enregistrer ce domaine afin de contourner le filtre. On ne va pas remplacer le deuxième point afin de conserver un domaine valide. On peut donc valider l’épreuve avec la charge utile https://www4acceis.fr/.
/^#{base_url}\/.*$/i.match?("https://www4acceis.fr/")
=> trueURL complète :
http://localhost:9292/acceis?redirect_url=https://www4acceis.fr/
2 – Injection de saut de ligne
Toujours concernant les expressions régulières, voici les caractéristiques des opérateurs suivants :
^– Début de chaine : Correspond au début d’une chaîne sans consommer de caractères. Si le mode multiligne/mest utilisé, la correspondance se fera également immédiatement après un caractère de nouvelle ligne transformant ainsi le début de chaine en début de ligne.$– Fin de chaine : Correspond à la fin d’une chaîne sans consommer de caractères. Si le mode multiligne/mest utilisé, la correspondance se fera également immédiatement avant un caractère de nouvelle ligne transformant ainsi la fin de chaine en fin de ligne.\A– Début de chaine : Ne correspond qu’au début d’une chaîne. Contrairement à^, cette fonction n’est pas affectée par le mode multiligne.\Z– Fin de chaine : Correspond à la fin d’une chaîne ou à la position avant la fin de la ligne juste à la fin de la chaîne (le cas échéant). Contrairement à$, cette fonction n’est pas affectée par le mode multiligne.\z– Fin de chaine absolue : Correspond uniquement à la fin d’une chaîne. Contrairement à$, cette fonction n’est pas affectée par le mode multiligne et, contrairement à\Z, elle ne correspond pas à la fin d’une chaîne avant un saut de ligne.
Dans la plupart des langages pour que ^ et $ se transforme de début/fin de chaine en début/fin de ligne, il faut utiliser le mode multiligne /m. Or une spécificité de Ruby est que ce mode est activé par défaut (ce qui est assez logique sinon ^ et \A font strictement la même chose et de même pour $ et \Z). En Ruby, le mode appelé multiligne /m fait en sorte que le point corresponde aux sauts de ligne, ce qui dans les autres langages s’appelle le mode ligne seule et se note /s.
Il est donc possible d’utiliser n’importe quelle URL suivie d’un saut de ligne suivi de https://www.acceis.fr/.
/^#{base_url}\/.*$/i.match?("https://pwn.by\nhttps://www.acceis.fr/")
=> trueAlors que, par exemple, cela n’aurait pas fonctionné sans /m en JavaScript :
base_url = 'https://www.acceis.fr';
RegExp(^${base_url}\/.*$).test("https://pwn.by\nhttps://www.acceis.fr/")
// => false
RegExp(^${base_url}\/.*$, 'm').test("https://pwn.by\nhttps://www.acceis.fr/")
// => trueBien sûr, pour que cela fonctionne en pratique, il faudra URL-encoder le saut de ligne \n, c’est-à-dire %0a. Cela donne donc l’URL complète suivante :
http://localhost:9292/acceis?redirect_url=https://pwn.by%0ahttps://www.acceis.fr/
3 – Collision de casse Unicode
Comme vous le savez, je (NDLR. noraj) suis assez fervent des détournements d’Unicode.
Oui, le mode /i qui se cachait sous vos yeux n’était pas anodin. En effet, /i pour "case insensitive" (insensible à la casse) veut dire que le moteur d’expression régulière va considérer que les caractères minuscules et majuscules sont égaux. Or la quasi-totalité des langages de programmation (modernes) utilisent des chaines Unicode (le plus souvent encodé en UTF-8 mais parfois aussi en UTF-16). Étant sensiblement plus complexe et étendu que l’ASCII, l’Unicode va donc devoir utiliser un algorithme permettant de comparer les différentes casses. Le "case folding" va donc effectuer une canonisation (différent de la normalisation) des caractères (voir ICU > Transforms > Case Mapping > Case Folding et UCD – Case Folding – Unicode 15.0.0).
On peut donc utiliser un utilitaire officiel d’Unicode afin de chercher tous les caractères qui se canonisent en s : https://util.unicode.org/UnicodeJsps/list-unicodeset.jsp?a=%5B%3AtoCasefold%3Ds%3A%5D. Il y a bien sûr lui-même s (U+0073, LATIN SMALL LETTER S), sa version majuscule S (U+0053, LATIN CAPITAL LETTER S) mais aussi ſ (U+017F, LATIN SMALL LETTER LONG S).
La charge utile suivante fonctionne donc (en Ruby, Python, Go) pour valider l’expression régulière (mais pas en PHP, JavaScript, Java, C#) :
/^#{base_url}\/.*$/i.match?("https://www.acceiſ.fr/")
# => trueURL complète :
- http://localhost:9292/acceis?redirect_url=https://www.acceiſ.fr/
- ou http://localhost:9292/acceis?redirect_url=https://www.accei%C5%BF.fr/ (URL-encodée)
Cependant, cela reste théorique, car en pratique les noms de domaines ne sont pas sensibles à la casse donc acceis.fr = acceiS.fr = acceiſ.fr. Tous les "registrars" vous diront donc que acceiſ.fr est déjà réservé puisque ce domaine est identique à acceis.fr.
Désolé pour les petits malins, mais dans la vraie vie ça ne fonctionne pas. Toutefois, c’est intéressant d’avoir cela à l’esprit pour les contextes sensibles à la casse.
Code corrigé
Voici donc le code corrigé :
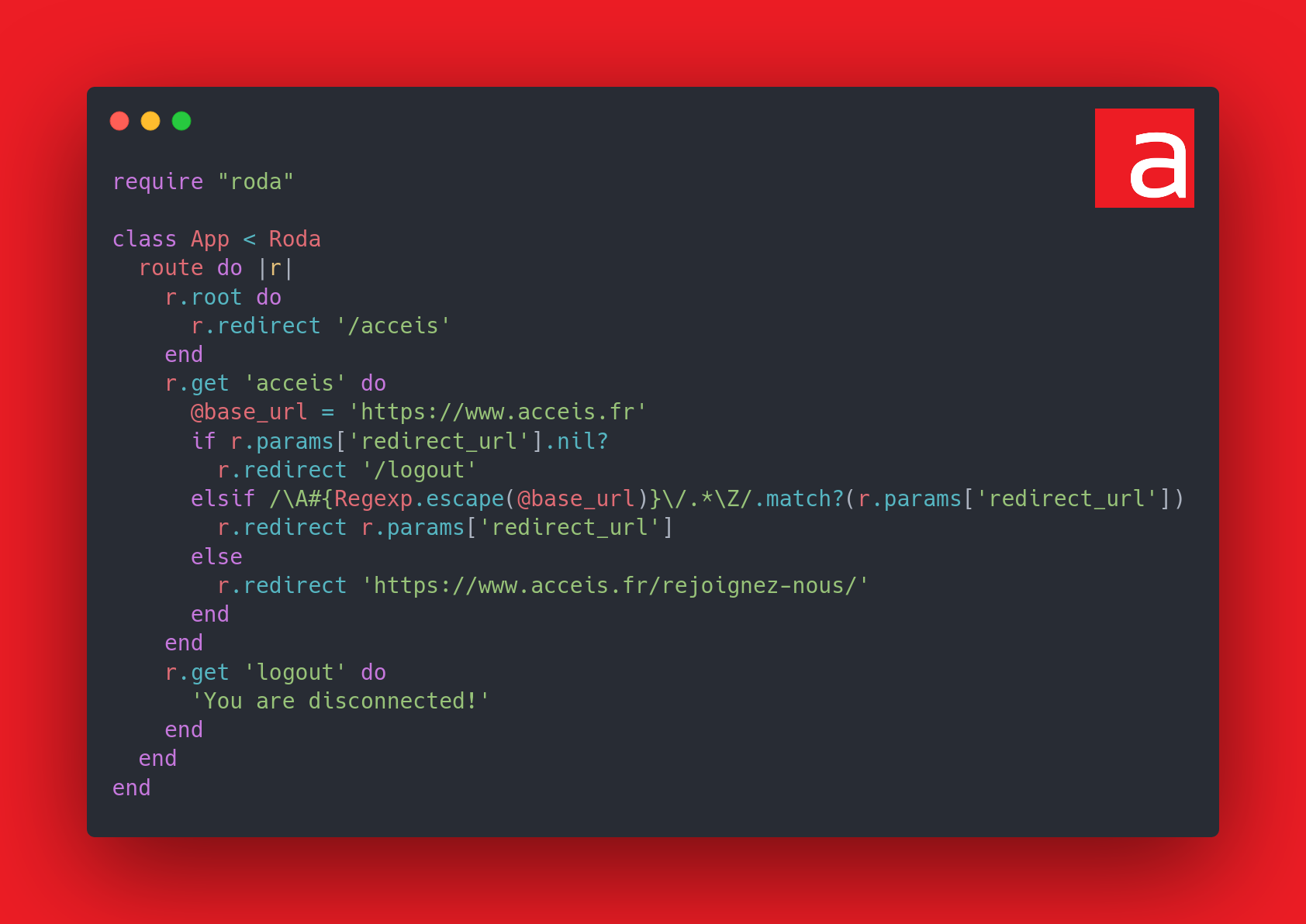
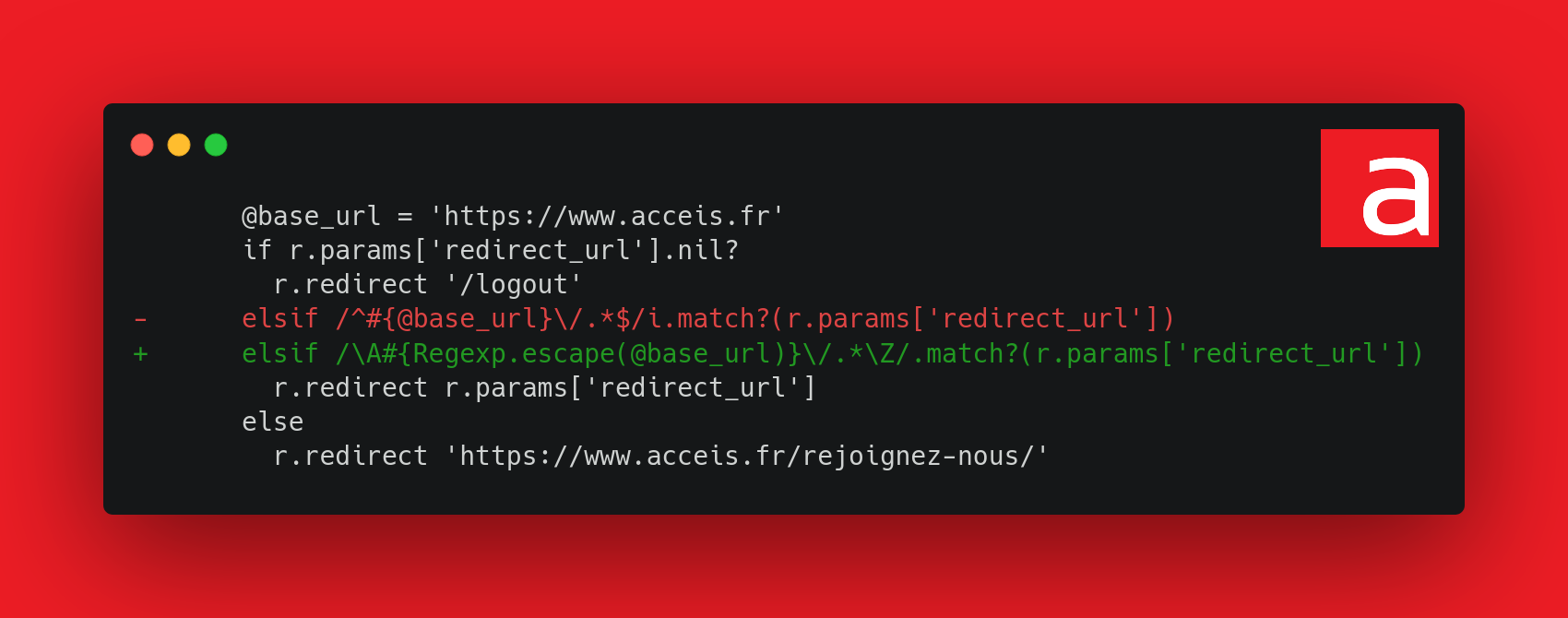
On a donc modifié les éléments suivants :
- Utilisation de
Regexp.escape()pour échapper les opérateurs d’expression régulière - Remplacement de
^et$par\Aet\Zafin d’ignorer les sauts de lignes - Suppression du mode insensible à la casse pour éviter la canonisation
Le code source est disponible sur le dépôt Github Acceis/vulnerable-code-snippets.
A propos de l’auteur
Article écrit par Alexandre ZANNI alias noraj, Ingénieur en Test d’Intrusion chez ACCEIS.