
![]()
Note: This article is also available in french 🇫🇷.
What the ffuf?
ffuf is the acronym of Fuzz Faster U Fool, it is a command line utility (CLI) intended for penetration testers (pentesters).
It is primarily a file and folder scanner for web applications.
The basic operation allows enumerating existing content on a web application by making queries from a list of common file and folder names. By observing the HTTP status codes, the application can determine whether the resource in question exists or not.
Many other such tools exist. So what makes ffuf special?
One of the precursors of the genre is a tool called dirb, this one is old, slow and depreciated, but was one of the first to see the light. dirb was limited to the functionality defined before: listing web resources.
Another old and deprecated tool of this kind, quite similar to dirb in terms of function but using a graphical interface (GUI) rather than the command line (CLI) was called dirbuster.
dirb is short for dirbuster although the two tools are distinct. Both are themselves short for Directory Buster (maybe in reference to the movie Ghost Buster).
Many other tools inspired by dirb and dirbuster have thus been named prefix + buster: feroxbuster, Lulzbuster, Gobuster, rustbuster. With the exception of rustbuster, these successors are also limited to enumerating web resources. The name of these tools is representative for their functionality.
However, as a reminder ffuf stands for Fuzz Faster U Fool. If ffuf is not named bfuf for Bust Faster U Fool there is a reason. The same logic applies to a counterpart named wfuzz. Their name includes the word fuzz and not buster because, in addition to enumerating web resources using word list attacks, both tools are capable of fuzzing.
But what is fuzzing?
I’ve already waffled a lot on the etymology of tools so I’ll try to be brief on the definition of fuzzing.
Generally speaking, fuzzing is a technique for testing software by injecting random or targeted data into a program’s inputs to observe its behavior in unexpected cases. If the program crashes, generates an error, or goes into a state that decreases its security level, then there are issues or vulnerabilities to be fixed.
You don’t necessarily need to know how the application works to fuzz it, but if you have information about it, you can use targeted test cases.
The counterparts of ffuf that only enumerate web resources only inject the test set in one place: after the URL, for example https://example.org/FUZZ_DATA. Also no dataset generator is supported, it is only possible to specify a file which will be a list of strings with one string per line.
Whereas ffuf can inject datasets anywhere: after the URL of course but also in GET or POST parameters, in HTTP headers, etc. The basic operation is simple, you just have to place the keyword FUZZ at the place where you want to inject the dataset. But later on, we will see that it is possible to use several datasets in parallel.
Moreover, ffuf not only reads a dataset from a file, it can also read datasets from the standard input (STDIN) or use the external generator Radamsa.
Advanced usage
I already covered the simplest and most common use cases in my room ffuf on TryHackMe.
Note: TryHackMe is a platform for learning and security challenges that is a bit special. Indeed, in addition to the labs, boxes and challenges that we knew at HackTheBox, TryHackMe also offers rooms in the form of courses, exercises, tutorials or let’s call them as we want. These rooms are not there to simply offer a technical challenge without any indication to the users of the platform but to offer a space where it is possible to learn with the help of a structured content that guides the user while teaching him certain notions in the form of courses / explanations that he must then reproduce by answering questions and/or by accomplishing small exercises that usually break a complete challenge into small missions.
In this TryHackMe room, you’ll find the following concepts:
- The basics
- Listing files and folders
- Using filters
- Fuzzing parameters
- Identifying vhosts and subdomains
- Passing ffuf traffic through a proxy
- Review of some useful options
This article will assume that you have already mastered these concepts and therefore poses this TryHackMe room as a prerequisite.
The concepts covered in this article are :
- The configuration file
- Reading from standard input and use case examples
- Avoiding false negatives with match all and filtering with regexp
- The use of external payload mutators
Note: In order to practice while reading this article, you can deploy the machine present in the ffuf TryHackMe room, use the ffufme docker image or use the online version of ffufme.
The configuration file
ffuf has a configuration file that allows you to change the default behavior and create shortcuts.
As stated in the official documentation, the location of this default configuration file will be $HOME/.ffufrc on Unix systems and %USERPROFILE%\.ffufrc on Microsoft Windows systems.
Note: if you want to participate in the implementation of reading a configuration file in a normalized location (XDG) for Unix systems, please refer to ticket ffuf#542.
Let’s start with a simple example, by default no colorization is enabled for the standard output (STDOUT).
ffuf -u http://ffuf.me/cd/basic/FUZZ -w /usr/share/seclists/Discovery/Web-Content/common.txt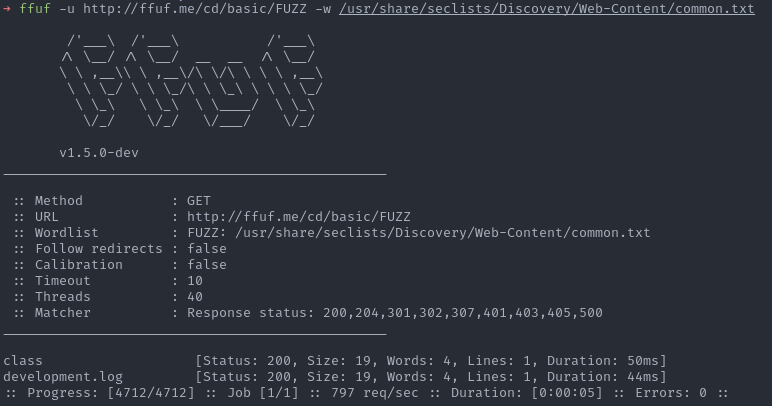
Note: the help message says that colorization is enabled by default, but this is wrong. Even with the latest public version (1.5.0), no color code is returned if the option is not present either in the CLI or in the configuration file (see colorize()).
-c Colorize output. (default: true)
You must then add the -c option to each command to take advantage of the color.
ffuf -u http://ffuf.me/cd/basic/FUZZ -w /usr/share/seclists/Discovery/Web-Content/common.txt -c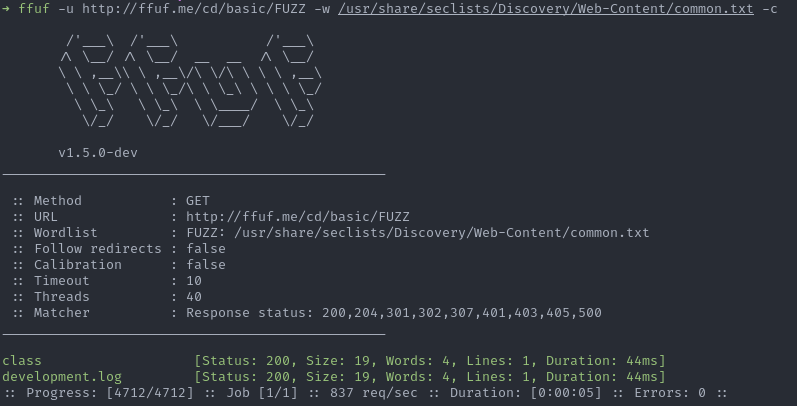
Rather than specifying this option at each command, it is possible to enable it permanently in the configuration file (e.g. ~/.ffufrc):
[general]
colors = trueNote: ffuf uses a configuration file in TOML v1.0.0 format with the help of the parser go-toml v2 (see source).
Now it is possible to enjoy the color without using the option.
ffuf -u http://ffuf.me/cd/basic/FUZZ -w /usr/share/seclists/Discovery/Web-Content/common.txt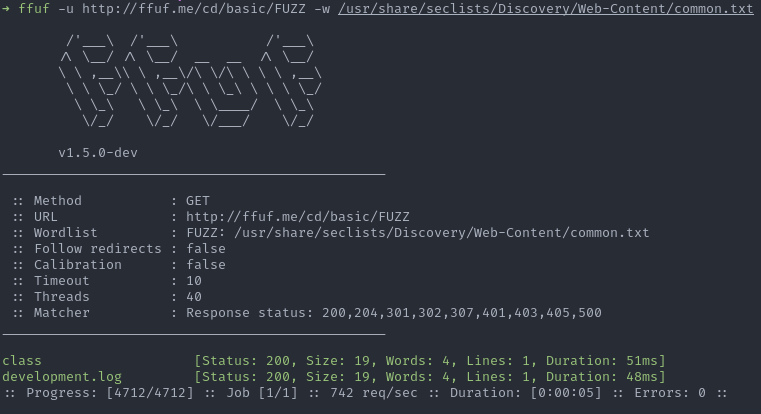
Note: ffuf does not provide any documentation for this configuration file, but it does provide an example file: ffufrc.example.
Now that we’ve got the concept down, let’s try some more useful scenarios.
The -config option allows you to define a custom configuration file, so you can define one configuration file per client for penetration testing (e.g. ~/Projects/clientXYZ.ffurc.toml).
For example, the client may have asked to add an HTTP header to each request in order to avoid sending false security alerts to the SOC (e.g. X-SOC-Tag: clientXYZ-audit042). The base URL will also be the same for the entire duration of the penetration test. Finally, you may want to log all the requests sent through a proxy in order to have traces allowing you to understand the origin of a potential malfunction on the application.
This gives the following configuration file:
[http]
headers = [
"X-SOC-Tag: clientXYZ-audit042",
]
proxyurl = "http://127.0.0.1:8080"
url = "http://ffuf.me/cd/basic/FUZZ"As well as the following command:
ffuf -config ~/Projets/clientXYZ.ffurc.toml -w /usr/share/seclists/Discovery/Web-Content/common.txtRather than the following command without a configuration file :
ffuf -u http://ffuf.me/cd/basic/FUZZ -w /usr/share/seclists/Discovery/Web-Content/common.txt -x "http://127.0.0.1:8080" -H "X-SOC-Tag: clientXYZ-audit042"As mentioned in the TryHackMe room, it is possible to specify a custom keyword for a dictionary or a command, which allows you to use several of them.
# 2 dictionaries
ffuf -u 'http://ffuf.me/cd/param/DIR?PARAM=1' -w /usr/share/seclists/Discovery/Web-Content/common.txt:DIR -w /usr/share/seclists/Discovery/Web-Content/burp-parameter-names.txt:PARAMIt is then possible to specify the dictionaries in the configuration file.
[input]
wordlists = [
"/usr/share/seclists/Discovery/Web-Content/common.txt:COMMON",
"/usr/share/seclists/Discovery/Web-Content/burp-parameter-names.txt:PARAM",
]# 2 dictionaries
ffuf -u 'http://ffuf.me/cd/param/COMMON?PARAM=1'Note: The current behavior of ffuf is quite annoying, as it raises an error when a dictionary is defined but not used cf. ffuf#572. This behavior can still be acceptable when using options via CLI but makes the use of the wordlists option in the configuration file almost useless.
Once this behavior is fixed, it will be possible to define a large list of dictionaries with aliases to avoid having to enter dictionary paths.
[input]
wordlists = [
"/usr/share/seclists/Discovery/Web-Content/common.txt:COMMON",
"/usr/share/seclists/Discovery/Web-Content/burp-parameter-names.txt:PARAM",
"/usr/share/seclists/Discovery/DNS/subdomains-top1million-5000.txt:SUBDOMAINS",
"/usr/share/seclists/Discovery/Web-Content/quickhits.txt:QUICKHITS",
"/usr/share/seclists/Discovery/Web-Content/raft-medium-files-lowercase.txt:MEDIUMFILES",
"/usr/share/seclists/Discovery/Web-Content/raft-medium-directories-lowercase.txt:MEDIUMDIR",
"/usr/share/seclists/Discovery/Web-Content/raft-medium-words-lowercase.txt:MEDIUMWORDS"
]When more than one dictionary is specified, it is possible to define which operation mode should be used. The same nomenclature as Burp Suite Pro Intruder has been kept.
-mode Multi-wordlist operation mode. Available modes: clusterbomb, pitchfork, sniper (default: clusterbomb)
This can be useful to find the credentials for a basic authentication.
[input]
inputmode = "clusterbomb"
wordlists = [
"/usr/share/seclists/Usernames/top-usernames-shortlist.txt:USER",
"/usr/share/seclists/Passwords/2020-200_most_used_passwords.txt:PASS"
]ffuf -u http://USER:PASS@ffuf.me/ -config ~/Projets/clientXYZ.ffurc.tomlNote: The pitchfork mode will be more useful if you have already built a list of valid identifiers.
Finally, by default, the following HTTP status codes trigger a match:
[matcher]
status = "200,204,301,302,307,401,403,405,500"It may be useful to edit this list to avoid false negatives. For example, before this PR the code 500 was not retained. However, code 500 is frequently observed when the application does not behave normally, which is often interesting for an auditor.
Read from standard input (STDIN)
It may be convenient to read a dataset from the standard input in order to use external programs:
seq 0 1000 | ffuf -u 'http://ffuf.me/cd/pipes/user?id=FUZZ' -w -It is even possible to use a custom keyword:
seq 0 1000 | ffuf -u 'http://ffuf.me/cd/pipes/user?id=INT' -w -:INTIt may be more comfortable to write a generator in your preferred language:
# With Ruby
ruby -e '(0..255).each{|i| puts i}' | ffuf -u 'http://ffuf.me/cd/pipes/user?id=FUZZ' -w -
ruby -e 'puts (0..255).to_a' | ffuf -u 'http://ffuf.me/cd/pipes/user?id=FUZZ' -w -
# With bash
for i in {0..255}; do echo $i; done | ffuf -u 'http://ffuf.me/cd/pipes/user?id=FUZZ' -w -
# With cook - https://github.com/giteshnxtlvl/cook
cook 0-255 | ffuf -u 'http://ffuf.me/cd/pipes/user?id=FUZZ' -w -It becomes immediately smarter to use a dynamic generator rather than having to generate lots of dictionaries that are not flexible and take up space.
Note: The endpoint http://ffuf.me/no/ is imaginary and does not exist.
# For all integers from 0 to 999999 with a padding of 6 digits
# replace
> wc /usr/share/seclists/Fuzzing/6-digits-000000-999999.txt
1000000 1000000 7000000 /usr/share/seclists/Fuzzing/6-digits-000000-999999.txt
> ffuf -u 'http://ffuf.me/no/?id=FUZZ' -w /usr/share/seclists/Fuzzing/6-digits-000000-999999.txt
# by
> cook 0-9 0-9 0-9 0-9 0-9 0-9 | ffuf -u 'http://ffuf.me/no/?id=FUZZ' -w -It is easy to fuzz the hexadecimal:
cook 0-9,a-f 0-9,a-f | ffuf -u 'http://ffuf.me/no/?hex=FUZZ' -w -Better yet, fuzz some path traversal, the pre-made lists are very bad for that.
$ cook '../*1-10'
../
../../
../../../
../../../../
../../../../../
../../../../../../
../../../../../../../
../../../../../../../../
../../../../../../../../../
../../../../../../../../../../
$ cook '../*1-10' | ffuf -u 'http://ffuf.me?file=PTetc/passwd' -w -:PT -v
...
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 93ms]
| URL | http://ffuf.me?file=../etc/passwd
* PT: ../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 59ms]
| URL | http://ffuf.me?file=../../../../../etc/passwd
* PT: ../../../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 45ms]
| URL | http://ffuf.me?file=../../../../../../../../../etc/passwd
* PT: ../../../../../../../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 44ms]
| URL | http://ffuf.me?file=../../../../etc/passwd
* PT: ../../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 56ms]
| URL | http://ffuf.me?file=../../../etc/passwd
* PT: ../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 56ms]
| URL | http://ffuf.me?file=../../../../../../../etc/passwd
* PT: ../../../../../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 56ms]
| URL | http://ffuf.me?file=../../etc/passwd
* PT: ../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 56ms]
| URL | http://ffuf.me?file=../../../../../../etc/passwd
* PT: ../../../../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 76ms]
| URL | http://ffuf.me?file=../../../../../../../../etc/passwd
* PT: ../../../../../../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 76ms]
| URL | http://ffuf.me?file=../../../../../../../../../../etc/passwdIf you want to avoid using ffuf-scripts – ffuf_basicauth.sh to generate a basic authentication:
# With cook
cook fz-http_default_users.txt : fz-http_default_pass.txt -m b64e | ffuf -u 'http://ffuf.me/no/api/info' -w - -H "Authorization: Basic FUZZ" -fc 403
# Without cook
ffuf -u http://USER:PASS@ffuf.me/api/info -w /usr/share/fuzzdb/wordlists-user-passwd/generic-listpairs/http_default_users.txt:USER -w /usr/share/fuzzdb/wordlists-user-passwd/generic-listpairs/http_default_pass.txt:PASS -fc 403Or to transform each entry in the list with md5 + base64 encoding:
# With cook
cook -f: /usr/share/fuzzdb/wordlists-user-passwd/generic-listpairs/http_default_users.txt f.md5.b64e | ffuf -u 'http://ffuf.me/no/api/user/FUZZ' -w -
# Without pencode
while read -r line; do echo -n $line | pencode md5 b64encode; echo ; done < /usr/share/fuzzdb/wordlists-user-passwd/generic-listpairs/http_default_users.txtIn short, you will have understood, it allows you to do quite powerful things.
Avoiding false negatives
By default, only the following HTTP status codes will be taken into account by ffuf : 200,204,301,302,307,401,403,405,500.
This will generally be appropriate for classical uses but we risk having false negatives if the application responds with other codes that are a little less frequent. For example, if the application responds with a 201 Created, 202 Accepted, 203 Non-Authoritative Information, 206 Partial Content, etc. we will miss some information.
To do this one can overwrite the default list and provide a more complete one with -mc (match code), e.g. -mc 200,201,202,203,204,206,301,302,307,401,403,405,500. But this might be a bit of a pain to provide an exhaustive list and it is not possible to add codes to the default list but only to overwrite the list. Fortunately, there is another solution. One can use the keyword all to capture all codes, e.g. -mc all. However, since -mc all will catch absolutely everything, you will see absolutely nothing if you don’t use any filter. The minimum will be to eliminate non-existent resources: -mc all -fc 404. If necessary, we can add 403,302 if the application generates false positives because of rewriting rules.
Another example, which I discuss in the ffuf TryHackMe room, is the use of filters with regexp.
Indeed, it is interesting to keep the 403 (Forbidden) codes, because this corresponds to existing resources but to which we do not have the authorization to access. This may indicate resources of interest that we can try to access with vulnerabilities, bypass techniques or once we have gained access, for example /admin/. The problem is that some proxies (proxy) can define rewrite rules that will generate false positives. In auditing we often get 403’s for all files starting with . or .ht, so the proxy rewrite rule will pollute our results with hundreds of 403’s that are false positives.
We can see these false positives on the DVWA application included in the ffuf TryHackMe room.
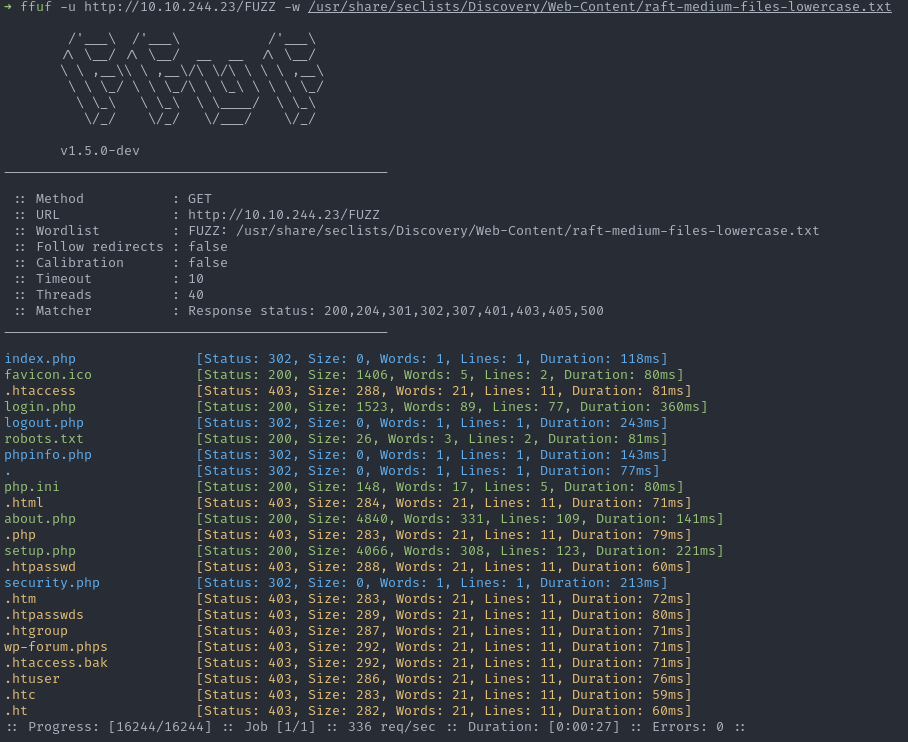
But it would be a pity to filter out all 403s completely and miss a /admin/ or other joys. To do this you can use the regular expression filter -fr (filter regexp), for example -fr '/\..*'.
Decomposition of the regular expression :
\.literally matches a dot., it is necessary to escape it with a backslash\.*matches any character any number of times\..*matches a dot followed by anything but this is not enough because the.phpofindex.phpalso matches this regexp, so it is necessary to indicate that the resource starts with a dot^is used to indicate the beginning of the string but^\..*doesn’t work and filters everything because the regexp must be applied to the whole URL and not just to the string that comes from the dictionary
So we’ll use a slash / to indicate that the resource starts with a dot because the slash is the URL separator: /\..*.
By replaying the same command with the filter in addition, the result is much more readable:
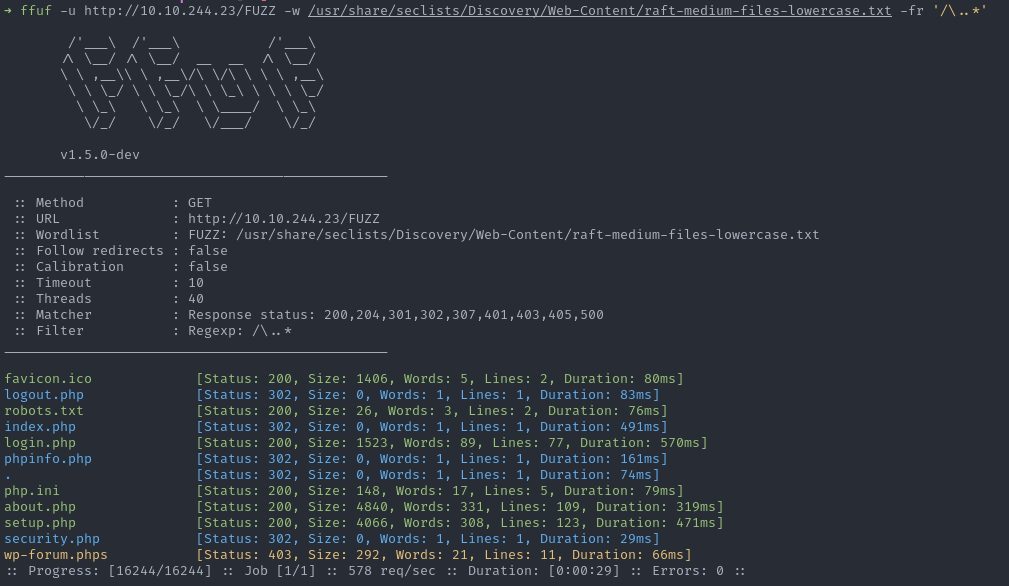
And it allows you to find the resource wp-forum.phps that you would not have seen if you had used a -fc 403.
Use of raw request file
Any pentester has already used this kind of command with SQLmap:
sqlmap -r req.txt --level 5 -p id --risk 3Indeed, the -r option of SQLmap allows giving it as input an HTTP request in raw format, as we can see with Wireshark or Burp Suite, which avoids having to specify a whole bunch of options to add a cookie, headers, the URL, etc.
For example:
GET /cd/pipes/user?id=1 HTTP/1.1
Host: ffuf.me
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:103.0) Gecko/20100101 Firefox/103.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1Well, the same mechanism is available in ffuf.
We can create the req.txt file and put our FUZZ keyword directly in it so we don’t have to redefine the URL.
GET /cd/pipes/user?id=FUZZ HTTP/1.1
Host: ffuf.me
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:103.0) Gecko/20100101 Firefox/103.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1Then you just have to specify the file that contains the request with -request and don’t forget -request-proto to tell ffuf to use HTTP instead of HTTPS. Otherwise HTTPS is used by default and the request will not succeed.
cook 1-1000 | ffuf -request /tmp/req.txt -w - -request-proto httpOtherwise, if one does not want to modify the file to change the location of the FUZZ keyword and test different parameters, one can always overwrite the URL with the -u parameter. In this case there is no need to specify -request-proto.
cook 1-1000 | ffuf -request /tmp/req.txt -w - -u 'http://ffuf.me/cd/pipes/user?otherparam=FUZZ'Mutator
ffuf can use an external payload mutator. The role of the mutator will be to randomly generate variations of the payload for fuzzing.
For example, here, I use Radamsa as a mutator to generate variations of an email address (sometimes valid, sometimes not). With -input-num I ask to generate 50 variations. The variation number will be exported to the FFUF_NUM environment variable. This allows it to be used as the seed (seed) of the mutator so that we can find out which payload was used.
ffuf --input-cmd 'echo "noraj@hackceis.fr" | radamsa --seed $FFUF_NUM' -input-num 50 -u http://ffuf.me/no/ -H "Content-Type: application/json" -X POST -d '{"email":"FUZZ"}'Indeed, ffuf will only display the variation number but this is sufficient to find the payload used.
1 [Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 57ms]
2 [Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 59ms]
3 [Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 68ms]
4 [Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 79ms]
10 [Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 49ms]$ echo "noraj@hackceis.fr" | radamsa --seed 2
noraj@hackceis.fraj@hacceis.fr.frRadamsa also works with files. For example, here is an XML file, test.xml:
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>In the same way, we will be able to generate XML file variations very simply.
ffuf --input-cmd 'radamsa --seed $FFUF_NUM test.xml' -input-num 50 -u http://ffuf.me/no/ -H "Content-Type: application/xml" -X POST -d 'FUZZ' -x http://127.0.0.1:8080Other options
Of course ffuf has options to limit the number of requests sent, handle timeouts, recursion, the number of threads, remove comments from a list, replace a keyword in a list that serves as a template, etc., but these are easy to learn by reading the following resources:
- the
ffuf --helphelp page - the codingo guide
- the ffuf TryHackMe room
- the Hacking article guide
About the author
Article written by Alexandre ZANNI aka noraj, Penetration Testing Engineer at ACCEIS.