
![]()
Note : Cet article est aussi disponible en anglais 🇬🇧.
Qu’est-ce que ffuf?
ffuf est l’acronyme de Fuzz Faster U Fool, c’est un utilitaire en ligne de commande (CLI) destiné aux auditeurs en test d’intrusion (pentesters).
C’est en premier lieu un scanneur de fichiers et dossiers pour application web.
Le fonctionnement de base permet d’énumérer du contenu existant sur une application web en faisant des requêtes à partir d’une liste de nom de fichiers et dossiers communs. L’observation des codes de statut HTTP permet à l’application de déterminer si la ressource en question existe ou non.
De nombreux autres outils de ce type existent. Alors qu’est-ce qui fait que ffuf soit spécial ?
L’un des précurseurs du genre est un outil nommé dirb, celui-ci est ancien, lent et déprécié, mais fut l’un des premiers à voir le jour. dirb était limité à la fonctionnalité définie auparavant : énumérer des ressources web.
Un autre outil du genre lui aussi ancien et déprécié, assez similaire à dirb en termes de fonctionnement mais utilisant une interface graphique (GUI) plutôt qu’en ligne de commande (CLI) était nommé dirbuster.
dirb est un diminutif de dirbuster bien que les deux outils soient distincts. Les deux étant eux-mêmes un diminutif de Directory Buster que l’on peut approximativement traduire en français par Chasseur de répertoires si l’on veut faire référence au film Ghost Buster ou plus vulgairement par choppeur de répertoires ou attrapeur de répertoires.
Bien d’autres outils inspirés de dirb et dirbuster se sont donc ainsi nommés préfixe + buster: feroxbuster, Lulzbuster, Gobuster, rustbuster. À l’exception de rustbuster, ces successeurs sont aussi limités à l’énumération de ressources web. Le nom de ces outils est représentatif de leur fonctionnalité.
Cependant, pour rappel ffuf veut dire Fuzz Faster U Fool. Si ffuf n’est pas nommé bfuf pour Bust Faster U Fool c’est bien qu’il y a une raison. La même logique s’applique à un homologue nommé wfuzz. Leur nom inclut le mot fuzz et pas buster car, en plus d’énumérer des ressources web à l’aide d’attaque par liste de mots, ces deux outils sont capables de fuzzer.
Mais qu’est-ce donc que le fuzzing ?
J’ai déjà beaucoup tergiversé sur l’étymologie des outils donc je vais tenter d’être bref sur la définition du fuzzing.
De manière générale, le fuzzing est une technique pour tester des logiciels en injectant des données aléatoires ou ciblées dans les entrées d’un programme afin d’observer son comportement dans des cas inattendus. Si le programme plante, génère une erreur ou passe dans un état qui diminue son niveau de sécurité alors il y a des défauts ou des vulnérabilités à corriger.
Il n’y a pas forcément besoin de connaître le fonctionnement de l’application pour la fuzzer, mais si l’on a des informations à ce sujet, on pourra utiliser des jeux de test ciblés.
Les homologues de ffuf qui ne font que de l’énumération de ressources web n’injectent le jeu de test qu’à un seul emplacement : à la suite de l’URL, par exemple https://example.org/FUZZ_DATA. De même aucun générateur de jeu de données n’est supporté, il n’est possible que de spécifier un fichier qui sera une liste de chaines de caractères avec une chaîne de caractères par ligne.
Alors que ffuf, lui, peut injecter des jeux de données n’importe où : à la suite de l’URL bien sûr mais aussi dans les paramètres GET ou POST, dans les entêtes HTTP, etc. Le fonctionnement de base est simple, il suffit de placer le mot-clé FUZZ à l’endroit où l’on souhaite injecter le jeu de données. Mais par la suite, nous verrons qu’il est possible utiliser plusieurs jeux de données en parallèle.
De plus, ffuf ne se contente pas de lire un jeu de données depuis un fichier, il peut aussi lire des jeux de données depuis l’entrée standard (STDIN) ou bien d’utiliser le générateur externe Radamsa.
Des usages avancés
J’ai déjà couvert les cas d’usage les plus simples et les plus communs dans ma room ffuf sur TryHackMe.
Note : TryHackMe est une plateforme d’apprentissage et de challenges de sécurité un peu particulière. En effet, en plus des labs, boxes et challenges que l’on connaissait à HackTheBox, TryHackMe propose aussi des salons (rooms) sous forme de cours, d’exercices, de travaux dirigés, de tutoriels ou appelons-les comme nous voulons. Ces salons ne sont pas là pour simplement proposer un défi technique sans indication aux utilisateurs de la plateforme mais pour offrir un espace où il est possible d’apprendre à l’aide d’un contenu structuré qui guide l’utilisateur tout en lui apprenant certaines notions sous forme de cours / explications qu’il doit ensuite restituer en répondant à des questions et/ou en accomplissant des petits exercices qui découpent généralement un challenge complet en petites missions.
Dans ce salon TryHackMe, on retrouve donc les notions suivantes :
- Les bases
- Énumérer des fichiers et des dossiers
- Utiliser les filtres
- Fuzzer des paramètres
- Identifier des vhosts et des sous-domaines
- Passer le trafic ffuf à travers un proxy
- Passage en revue de quelques options utiles
Cet article supposera que vous maîtrisez déjà ces concepts et pose donc ce salon TryHackMe en prérequis.
Les notions abordées dans cet article sont :
- Le fichier de configuration
- Lire depuis l’entrée standard et exemples de cas d’usage
- Éviter les faux négatifs avec la match all et le filtre avec regexp
- L’utilisation de mutateurs externes de charge utile
Note : Afin de vous exercer tout en lisant cet article, vous pouvez déployer la machine présente dans le salon ffuf TryHackMe, utiliser l’image docker ffufme ou bien utiliser la version en ligne de ffufme.
Le fichier de configuration
ffuf possède un fichier de configuration permettant de modifier le comportement par défaut et de créer des raccourcis.
Comme indiqué dans la documentation officielle, l’emplacement de ce fichier de configuration par défaut sera $HOME/.ffufrc sur les systèmes Unix et %USERPROFILE%.ffufrc sur les systèmes Microsoft Windows.
Note : si vous souhaitez participer à l’implémentation de la lecture d’un fichier de configuration dans un emplacement normalisé (XDG) pour les systèmes Unix, veuillez vous référer au ticket ffuf#542.
Commençons par un exemple simple, par défaut aucune colorisation n’est activée pour la sortie standard (STDOUT).
ffuf -u http://ffuf.me/cd/basic/FUZZ -w /usr/share/seclists/Discovery/Web-Content/common.txt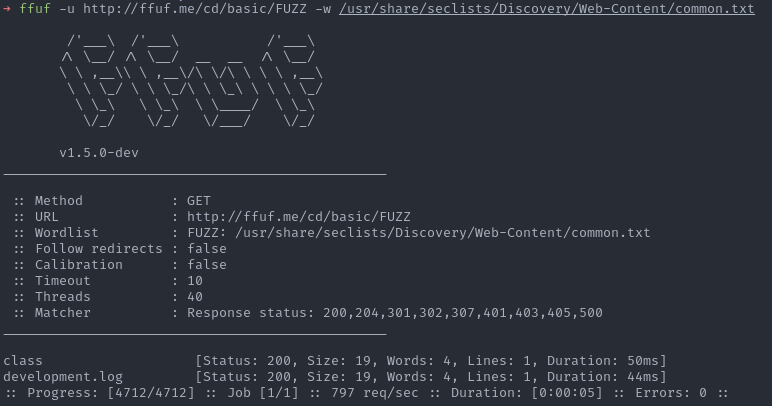
Note : le message d’aide dit que la colorisation est activée par défaut, mais cela est faux. Même avec la dernière version publique (1.5.0), aucun code couleur n’est retourné si l’option n’est pas présente soit en CLI soit dans le fichier de configuration (cf. colorize()).
-c Colorize output. (default: true)
Il faut alors ajouter l’option -c à chaque commande pour profiter de la couleur.
ffuf -u http://ffuf.me/cd/basic/FUZZ -w /usr/share/seclists/Discovery/Web-Content/common.txt -c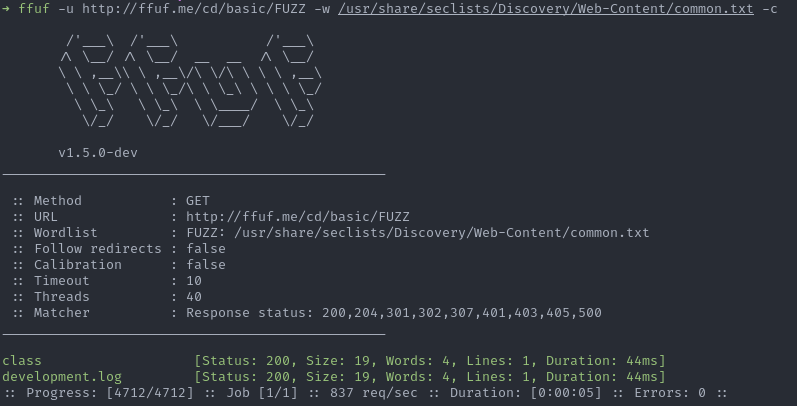
Plutôt que de spécifier cette option à chaque commande, il est possible de l’activer de manière permanente dans le fichier de configuration (ex. : ~/.ffufrc) :
[general]
colors = trueNote : ffuf utilise un fichier de configuration au format TOML v1.0.0 à l’aider du parser go-toml v2 (cf. source).
Maintenant il est possible de profiter de la couleur sans utiliser l’option.
ffuf -u http://ffuf.me/cd/basic/FUZZ -w /usr/share/seclists/Discovery/Web-Content/common.txt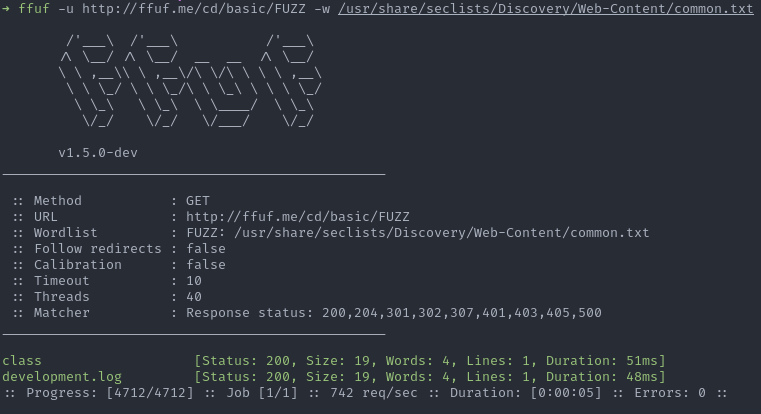
Note : ffuf ne fournit pas de documentation à proprement parler pour ce fichier de configuration mais donne un fichier example : ffufrc.example.
Maintenant que nous avons appréhendé le concept, essayons d’aborder des scénarios plus utiles.
L’option -config permet de définir un fichier de configuration personnalisé, on peut donc définir un fichier de configuration par client dans le cadre de test d’intrusion (ex. : ~/Projets/clientXYZ.ffurc.toml).
Par exemple, le client peut avoir demandé d’ajouter un en-tête HTTP à chaque requête afin d’éviter de remonter de fausses alertes de sécurité à son centre de supervision (SOC) (ex. : X-SOC-Tag: clientXYZ-audit042). L’URL de base sera également la même pour toute la durée du test d’intrusion. Enfin on peut vouloir journaliser toutes les requêtes envoyées à l’aide d’un proxy afin d’avoir des traces permettant de comprendre l’origine d’un potentiel dysfonctionnement sur l’application.
Cela donne le fichier de configuration suivant :
[http]
headers = [
"X-SOC-Tag: clientXYZ-audit042",
]
proxyurl = "http://127.0.0.1:8080"
url = "http://ffuf.me/cd/basic/FUZZ"Ainsi que la commande suivante :
ffuf -config ~/Projets/clientXYZ.ffurc.toml -w /usr/share/seclists/Discovery/Web-Content/common.txtPlutôt que la commande suivante sans fichier de configuration :
ffuf -u http://ffuf.me/cd/basic/FUZZ -w /usr/share/seclists/Discovery/Web-Content/common.txt -x "http://127.0.0.1:8080" -H "X-SOC-Tag: clientXYZ-audit042"Comme indiqué dans le salon TryHackMe, il est possible de spécifier un mot-clé personnalisé pour un dictionnaire ou une commande, ce qui permet d’ailleurs d’en utiliser plusieurs.
# 2 dictionnaires
ffuf -u 'http://ffuf.me/cd/param/DIR?PARAM=1' -w /usr/share/seclists/Discovery/Web-Content/common.txt:DIR -w /usr/share/seclists/Discovery/Web-Content/burp-parameter-names.txt:PARAMIl est alors possible de spécifier les dictionnaires dans le fichier de configuration.
[input]
wordlists = [
"/usr/share/seclists/Discovery/Web-Content/common.txt:COMMON",
"/usr/share/seclists/Discovery/Web-Content/burp-parameter-names.txt:PARAM",
]# 2 dictionnaires
ffuf -u 'http://ffuf.me/cd/param/COMMON?PARAM=1'Note : Le comportement actuel de ffuf est assez gênant, car il lève une erreur lorsqu’un dictionnaire est défini mais non utilisé cf. ffuf#572. Ce comportement peut encore passer lorsqu’on utilise les options via CLI mais rend l’utilisation de l’option wordlists dans le fichier de configuration quasiment inutile.
Une fois ce comportement corrigé, il sera possible de définir une vaste liste de dictionnaires avec des alias pour éviter d’avoir à saisir les chemins des dictionnaires.
[input]
wordlists = [
"/usr/share/seclists/Discovery/Web-Content/common.txt:COMMON",
"/usr/share/seclists/Discovery/Web-Content/burp-parameter-names.txt:PARAM",
"/usr/share/seclists/Discovery/DNS/subdomains-top1million-5000.txt:SUBDOMAINS",
"/usr/share/seclists/Discovery/Web-Content/quickhits.txt:QUICKHITS",
"/usr/share/seclists/Discovery/Web-Content/raft-medium-files-lowercase.txt:MEDIUMFILES",
"/usr/share/seclists/Discovery/Web-Content/raft-medium-directories-lowercase.txt:MEDIUMDIR",
"/usr/share/seclists/Discovery/Web-Content/raft-medium-words-lowercase.txt:MEDIUMWORDS"
]Lorsque plusieurs dictionnaires sont spécifiés, il est possible de définir quel mode d’opération doit être utilisé. La même nomenclature que Burp Suite Pro Intruder a été conservée.
-mode Multi-wordlist operation mode. Available modes: clusterbomb, pitchfork, sniper (default: clusterbomb)
Cela peut être utile pour trouver les identifiants d’une authentification basique.
[input]
inputmode = "clusterbomb"
wordlists = [
"/usr/share/seclists/Usernames/top-usernames-shortlist.txt:USER",
"/usr/share/seclists/Passwords/2020-200_most_used_passwords.txt:PASS"
]ffuf -u http://USER:PASS@ffuf.me/ -config ~/Projets/clientXYZ.ffurc.tomlNote : Le mode pitchfork sera plus utile si vous avez déjà constitué une liste d’identifiants valides.
Enfin, par défaut, les codes de statuts HTTP suivants déclenchent une correspondance :
[matcher]
status = "200,204,301,302,307,401,403,405,500"Il peut être utile d’éditer cette liste afin d’éviter les faux négatifs. Par exemple, avant cette PR le code 500 n’était pas retenu. Or le code 500 est fréquemment observé lorsque l’application ne se comporte pas normalement, ce qui est souvent intéressant pour un auditeur.
Lire depuis l’entrée standard (STDIN)
Il peut être pratique de lire un jeu de données depuis l’entrée standard afin d’utiliser des programmes externes :
seq 0 1000 | ffuf -u 'http://ffuf.me/cd/pipes/user?id=FUZZ' -w -Il est même possible d’utiliser un mot-clé personnalisé :
seq 0 1000 | ffuf -u 'http://ffuf.me/cd/pipes/user?id=INT' -w -:INTIl peut être plus confortable d’écrire un générateur avec son langage de prédilection :
# Avec Ruby
ruby -e '(0..255).each{|i| puts i}' | ffuf -u 'http://ffuf.me/cd/pipes/user?id=FUZZ' -w -
ruby -e 'puts (0..255).to_a' | ffuf -u 'http://ffuf.me/cd/pipes/user?id=FUZZ' -w -
# Avec bash
for i in {0..255}; do echo $i; done | ffuf -u 'http://ffuf.me/cd/pipes/user?id=FUZZ' -w -
# Avec cook - https://github.com/giteshnxtlvl/cook
cook 0-255 | ffuf -u 'http://ffuf.me/cd/pipes/user?id=FUZZ' -w -Cela devient tout de suite plus intelligent d’utiliser un générateur dynamique plutôt que de devoir générer des tas de dictionnaires qui ne sont pas flexibles et qui prennent de la place.
Note : L’endpoint http://ffuf.me/no/ est imaginaire et n’existe pas.
# Pour tous les entiers de 0 à 999999 avec un padding de 6 chiffres
# remplacer
> wc /usr/share/seclists/Fuzzing/6-digits-000000-999999.txt
1000000 1000000 7000000 /usr/share/seclists/Fuzzing/6-digits-000000-999999.txt
> ffuf -u 'http://ffuf.me/no/?id=FUZZ' -w /usr/share/seclists/Fuzzing/6-digits-000000-999999.txt
# par
> cook 0-9 0-9 0-9 0-9 0-9 0-9 | ffuf -u 'http://ffuf.me/no/?id=FUZZ' -w -On peut facilement fuzzer de l’hexadécimal :
cook 0-9,a-f 0-9,a-f | ffuf -u 'http://ffuf.me/no/?hex=FUZZ' -w -Mieux, fuzzer du path traversal, les listes préétablies sont très nulles pour ça.
$ cook '../*1-10'
../
../../
../../../
../../../../
../../../../../
../../../../../../
../../../../../../../
../../../../../../../../
../../../../../../../../../
../../../../../../../../../../
$ cook '../*1-10' | ffuf -u 'http://ffuf.me?file=PTetc/passwd' -w -:PT -v
...
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 93ms]
| URL | http://ffuf.me?file=../etc/passwd
* PT: ../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 59ms]
| URL | http://ffuf.me?file=../../../../../etc/passwd
* PT: ../../../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 45ms]
| URL | http://ffuf.me?file=../../../../../../../../../etc/passwd
* PT: ../../../../../../../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 44ms]
| URL | http://ffuf.me?file=../../../../etc/passwd
* PT: ../../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 56ms]
| URL | http://ffuf.me?file=../../../etc/passwd
* PT: ../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 56ms]
| URL | http://ffuf.me?file=../../../../../../../etc/passwd
* PT: ../../../../../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 56ms]
| URL | http://ffuf.me?file=../../etc/passwd
* PT: ../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 56ms]
| URL | http://ffuf.me?file=../../../../../../etc/passwd
* PT: ../../../../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 76ms]
| URL | http://ffuf.me?file=../../../../../../../../etc/passwd
* PT: ../../../../../../../../
[Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 76ms]
| URL | http://ffuf.me?file=../../../../../../../../../../etc/passwdSi vous souhaitez éviter d’utiliser ffuf-scripts – ffuf_basicauth.sh afin de générer une authentification basique :
# Avec cook
cook fz-http_default_users.txt : fz-http_default_pass.txt -m b64e | ffuf -u 'http://ffuf.me/no/api/info' -w - -H "Authorization: Basic FUZZ" -fc 403
# Sans cook
ffuf -u http://USER:PASS@ffuf.me/api/info -w /usr/share/fuzzdb/wordlists-user-passwd/generic-listpairs/http_default_users.txt:USER -w /usr/share/fuzzdb/wordlists-user-passwd/generic-listpairs/http_default_pass.txt:PASS -fc 403Ou encore pour transformer chaque entrée de la liste avec md5 + encodage base64 :
# Avec cook
cook -f: /usr/share/fuzzdb/wordlists-user-passwd/generic-listpairs/http_default_users.txt f.md5.b64e | ffuf -u 'http://ffuf.me/no/api/user/FUZZ' -w -
# Avec pencode
while read -r line; do echo -n $line | pencode md5 b64encode; echo ; done < /usr/share/fuzzdb/wordlists-user-passwd/generic-listpairs/http_default_users.txtBref vous l’aurez compris, ca permet de faire des choses assez puissantes.
Éviter les faux négatifs
Par défaut, seuls les codes de status HTTP suivants vont être pris en compte par ffuf : 200,204,301,302,307,401,403,405,500.
Cela conviendra en général pour les usages classiques mais nous risquons d’avoir des faux négatifs si l’application répond avec d’autres codes un peu moins fréquents. Par exemple si l’application répond avec un 201 Created, 202 Accepted, 203 Non-Authoritative Information, 206 Partial Content, etc. nous allons rater de l’information.
Pour cela on peut écraser la liste par défaut et en fournir une plus complète avec -mc (match code), par exemple : -mc 200,201,202,203,204,206,301,302,307,401,403,405,500. Mais cela risque d’être un peu pénible pour fournir une liste exhaustive et il n’est pas possible d’ajouter des codes à la liste par défaut mais seulement d’écraser la liste. Heureusement il y a une autre solution. On peut utiliser le mot-clé all pour capter tous les codes, ex. : -mc all. Par contre comme -mc all va absolument tout récupérer, on ne verra absolument rien si l’on n’utilise aucun filtre. Le minimum sera d’éliminer les ressources inexistantes : -mc all -fc 404. On pourra rajouter au besoin 403,302 si l’application génère des faux positifs à cause de règles de ré-écriture.
Un autre exemple, que j’aborde dans le salon ffuf TryHackMe, est l’utilisation de filtre avec regexp.
En effet, il est intéressant de conserver les codes 403 (Forbidden), car cela correspond à des ressources existantes mais auxquelles nous n’avons pas l’autorisation d’accéder. Cela peut donc indiquer des ressources d’intérêt auxquelles nous pourrons tenter d’accéder avec des vulnérabilités, des techniques de contournement ou une fois que nous aurons récupéré des accès, par exemple /admin/. Le problème c’est que certains serveurs mandataires (proxy) peuvent définir des règles de réécriture qui vont générer des faux positifs. En audit on obtient souvent des 403 pour tous les fichiers qui commencent par . ou .ht, la règle de réécriture du proxy va donc venir polluer nos résultats avec des centaines de 403 qui sont des faux positifs.
On voit bien ces faux positifs sur l’application DVWA inclus dans le salon ffuf TryHackMe.
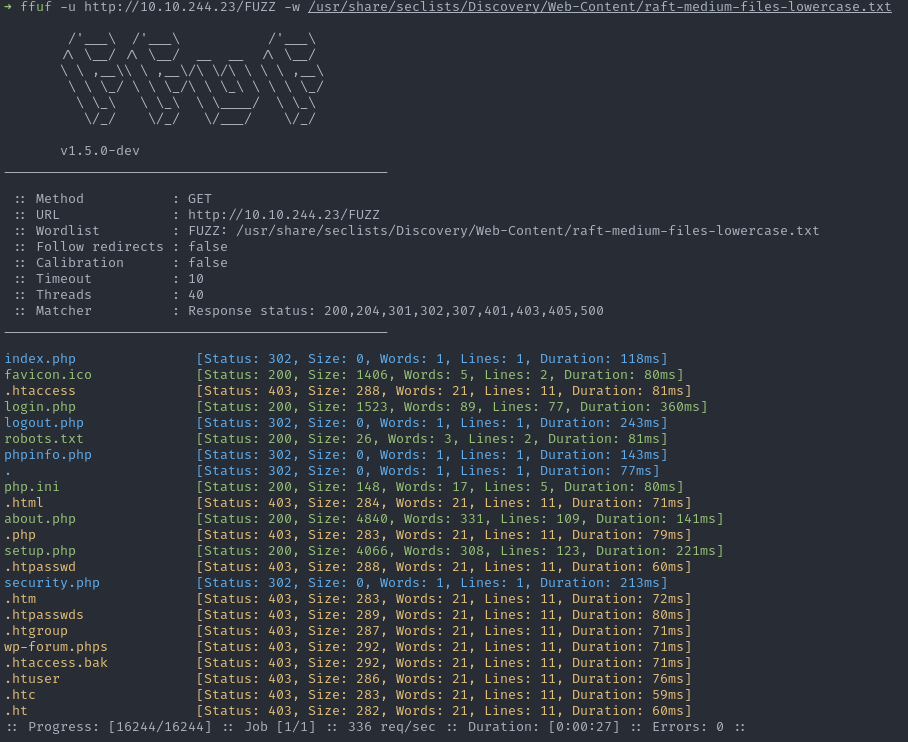
Mais il serait dommage de filtrer complètement toutes les 403 et de passer à côté d’un /admin/ ou autres joyeusetés. Pour ce faire on peut utiliser le filtre par expression régulière -fr (filter regexp), par exemple -fr '/..*'.
Décomposition de l’expression régulière :
\.correspond littéralement à un point., il est nécessaire l’échapper avec un anti-slash\.*correspond à n’importe caractère n’importe quel nombre de fois\..*correspond à un point suivi de n’importe quoi mais ce n’est pas suffisent car le.phpdeindex.phpcorrespond aussi à cette regexp, il faut donc indiquer que la ressource commence par un point^sert à indiquer le début de la chaîne mais^\..*ne fonctionne pas et filtre tout car la regexp doit être appliquée à l’URL entière et pas simplement à la chaîne qui provint du dictionnaire
On va donc utiliser un slash / pour indiquer que la ressource commence par un point car le slash est le séparateur d’URL : /..*.
En rejouant la même commande avec le filtre en plus, le résultat est bien plus lisible :
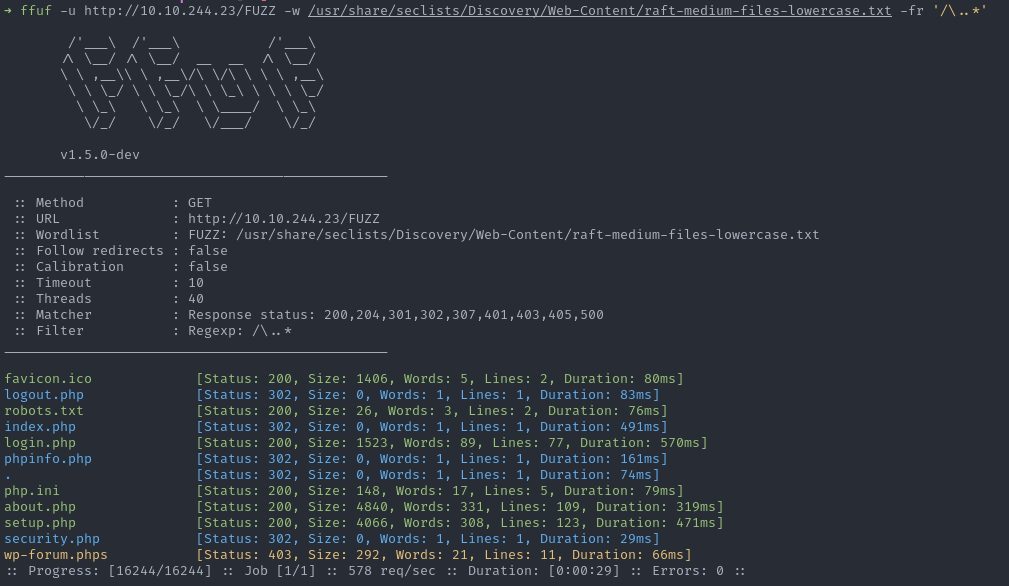
Et cela permet de trouver la ressource wp-forum.phps que l’on n’aurait pas vue si l’on avait utilisé un -fc 403.
Utilisation de fichier de requête brute
Tout pentester a déjà utilisé ce genre de commande avec SQLmap :
sqlmap -r req.txt --level 5 -p id --risk 3En effet, l’option -r de SQLmap permet de lui donner en entrée une requête HTTP au format brut, telle que l’on observe avec Wireshark ou dans Burp Suite, ce qui évite d’avoir à préciser tout un tas d’options pour ajouter un cookie, des en-têtes, l’URL, etc.
Par exemple :
GET /cd/pipes/user?id=1 HTTP/1.1
Host: ffuf.me
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:103.0) Gecko/20100101 Firefox/103.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1Et bien le même mécanisme est disponible dans ffuf.
On peut créer le fichier req.txt et placer notre mot-clé FUZZ directement dedans pour ne pas avoir à redéfinir l’URL.
GET /cd/pipes/user?id=FUZZ HTTP/1.1
Host: ffuf.me
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:103.0) Gecko/20100101 Firefox/103.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1Il suffit ensuite de spécifier le fichier qui contient la requête avec -request et surtout ne pas oublier -request-proto pour préciser à ffuf d’utiliser HTTP au lieu d’HTTPS. Car sinon HTTPS est utilisé par défaut et la requête ne va pas aboutir.
cook 1-1000 | ffuf -request /tmp/req.txt -w - -request-proto httpSinon, si l’on ne veut pas modifier le fichier pour changer l’emplacement du mot-clé FUZZ et tester différents paramètres, on peut toujours écraser l’URL avec le paramètre -u. Dans ce cas il n’y a plus besoin de spécifier -request-proto.
cook 1-1000 | ffuf -request /tmp/req.txt -w - -u 'http://ffuf.me/cd/pipes/user?otherparam=FUZZ'Mutateur
ffuf peut utiliser un mutateur externe de charge utile. Le rôle du mutateur va être de générer aléatoirement des variations de la charge utile pour fuzzer.
Par exemple ici, j’utilise Radamsa comme mutateur pour générer des variations d’une adresse email (parfois valide, parfois non). Avec -input-num je demande de générer 50 variations. Le numéro de la variation sera exporté dans la variable d’environnement FFUF_NUM. Ce qui permet de l’utiliser comme graine (seed) du mutateur afin de pouvoir retrouver quelle charge a été utilisée.
ffuf --input-cmd 'echo "noraj@hackceis.fr" | radamsa --seed $FFUF_NUM' -input-num 50 -u http://ffuf.me/no/ -H "Content-Type: application/json" -X POST -d '{"email":"FUZZ"}'En effet, ffuf affichera uniquement le numéro de variation mais cela est suffisant pour retrouver la charge utilisée.
1 [Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 57ms]
2 [Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 59ms]
3 [Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 68ms]
4 [Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 79ms]
10 [Status: 200, Size: 1495, Words: 230, Lines: 40, Duration: 49ms]$ echo "noraj@hackceis.fr" | radamsa --seed 2
noraj@hackceis.fraj@hacceis.fr.frRadamsa fonctionne aussi avec des fichiers. Par exemple voici un fichier XML, test.xml :
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>De la même manière, nous allons pouvoir générer des variations de fichier XML très simplement.
ffuf --input-cmd 'radamsa --seed $FFUF_NUM test.xml' -input-num 50 -u http://ffuf.me/no/ -H "Content-Type: application/xml" -X POST -d 'FUZZ' -x http://127.0.0.1:8080Autres options
Bien sûr ffuf possède des options pour limiter le nombre de requêtes envoyées, gérer les timeouts, la récursion, le nombre de threads, supprimer les commentaires d’une liste, remplacer un mot-clé dans une liste qui sert de modèle, etc., mais celles-ci sont simples à prendre en main en lisant les ressources suivantes :
- la page d’aide
ffuf --help - le guide de codingo
- salon ffuf TryHackMe
- le guide Hacking article
A propos de l’auteur
Article écrit par Alexandre ZANNI alias noraj, Ingénieur en Test d’Intrusion chez ACCEIS.