
n°1 – Open-Redirect – Solutions
The vulnerability to be detected for this challenge was an arbitrary redirect ("open-redirect"). At least three solutions were possible to solve this challenge. Solving the challenge does not necessarily require knowledge of the language (Ruby) or the web framework (Roda). Indeed, the problem was rather focused on transversal concepts and the use of regular expressions (Regexp).
Among the possible solutions, we find:
- Non escaping of the regular expression
- Start of line versus start of string, line feed injection
- Unicode case collision
Note: This article is also available in french 🇫🇷. The challenge was announced in this tweet 🐦.
1 – Non escaping of the regular expression
The interesting part of the code is the following:
@base_url = 'https://www.acceis.fr'
...
elsif /^#{@base_url}\/.*$/i.match?(r.params['redirect_url'])
r.redirect r.params['redirect_url']The string interpolation mechanism is quite common and consists of evaluating the contents of a string to replace variables with their values, for example:
"I am #{age} years old."in Rubyprintf("I am %d years old.", age);in C$"I am {age} years old.";in C#"I am $age years old."in PHPprintln!("I am {} years old.", age)in Rust
Here the principle is the same but it is regular expression interpolation, in other words the content of the variable is inserted into the regular expression, as is.
The regular expression thus becomes:
/^https:\/\/www.acceis.fr\/.*$/iIn a regular expression, the dot character . replaces any other character. So we can replace the first dot in the domain with any other character and register that domain to bypass the filter. We will not replace the second dot in order to keep a valid domain. We can therefore validate the test with the payload https://www4acceis.fr/.
/^#{base_url}\/.*$/i.match?("https://www4acceis.fr/")
=> trueFull URL:
http://localhost:9292/acceis?redirect_url=https://www4acceis.fr/
2 – Line feed injection
Still on the subject of regular expressions, here are the characteristics of the following operators:
^– Start of string: Matches the beginning of a string without consuming any characters. If the/mmultiline mode is used, the match will also be made immediately after a newline character, thus turning the start of a string into the beginning of a line.$– End of string: Matches the end of a string without consuming any characters. If the/mmulti-line mode is used, it will also match immediately before a newline character, making the end of string the end of line.\A– Start of string: Matches only the beginning of a string. Unlike^, this function is not affected by multiline mode.\Z– End of string: Matches the end of a string or the position before the end of the line right at the end of the string (if any). Unlike$, this function is not affected by multiline mode.\z– Absolute end of string: Matches only the end of a string. Unlike$, this function is not affected by multi-line mode and, unlike\Z, it does not match the end of a string before a line break.
In most languages, in order for ^ and $ to change from the beginning/end of a string to the beginning/end of a line, you have to use the /m multiline mode. In Ruby, this mode is enabled by default (which makes sense, otherwise ^ and \A do the same thing, and $ and \Z do the same thing). In Ruby, the mode called multi-line /m makes the dot correspond to the line breaks, which in other languages is called line-only mode and is noted /s.
So you can use any URL followed by a line break followed by https://www.acceis.fr/.
/^#{base_url}\/.*$/i.match?("https://pwn.by\nhttps://www.acceis.fr/")
=> trueWhereas, for example, it wouldn’t have worked without /m in JavaScript:
base_url = 'https://www.acceis.fr';
RegExp(^${base_url}\/.*$).test("https://pwn.by\nhttps://www.acceis.fr/")
// => false
RegExp(^${base_url}\/.*$, 'm').test("https://pwn.by\nhttps://www.acceis.fr/")
// => trueOf course, for this to work in practice, it will be necessary to URL-encode the linefeed \n, i.e. %0a. This gives the following complete URL:
http://localhost:9292/acceis?redirect_url=https://pwn.by%0ahttps://www.acceis.fr/
3 – Unicode case collision
As you know, I’m quite fond of Unicode hijackings.
Yes, the /i mode that was hiding in plain sight was not trivial. Indeed, /i for "case insensitive" means that the regular expression engine will consider upper and lower case characters as equal. However, almost all (modern) programming languages use Unicode strings (most often encoded in UTF-8 but sometimes also in UTF-16). Being significantly more complex and extensive than ASCII, Unicode will have to use an algorithm to compare the different case. Case folding will therefore perform a canonization (different from normalization) of characters (see ICU > Transforms > Case Mapping > Case Folding and UCD – Case Folding – Unicode 15.0.0).
One can therefore use an official Unicode utility to search for all characters that canonize as s: https://util.unicode.org/UnicodeJsps/list-unicodeset.jsp?a=%5B%3AtoCasefold%3Ds%3A%5D. There is of course s itself (U+0073, LATIN SMALL LETTER S), its uppercase version S (U+0053, LATIN CAPITAL LETTER S) but also ſ (U+017F, LATIN SMALL LETTER LONG S).
The following payload therefore works (in Ruby, Python, Go) to validate the regular expression (but not in PHP, JavaScript, Java, C#):
/^#{base_url}\/.*$/i.match?("https://www.acceiſ.fr/")
# => trueFull URL:
- http://localhost:9292/acceis?redirect_url=https://www.acceiſ.fr/
- or http://localhost:9292/acceis?redirect_url=https://www.accei%C5%BF.fr/ (URL-encoded)
However, this remains theoretical, because in practice domain names are not case sensitive so acceis.fr = acceiS.fr = acceiſ.fr. All the registrars will tell you that acceiſ.fr is already reserved since it is identical to acceis.fr.
Sorry for the smart guys, but in real life this doesn’t work. However, it’s worth bearing this in mind for case-sensitive contexts.
Fixed code
Here is the corrected code:
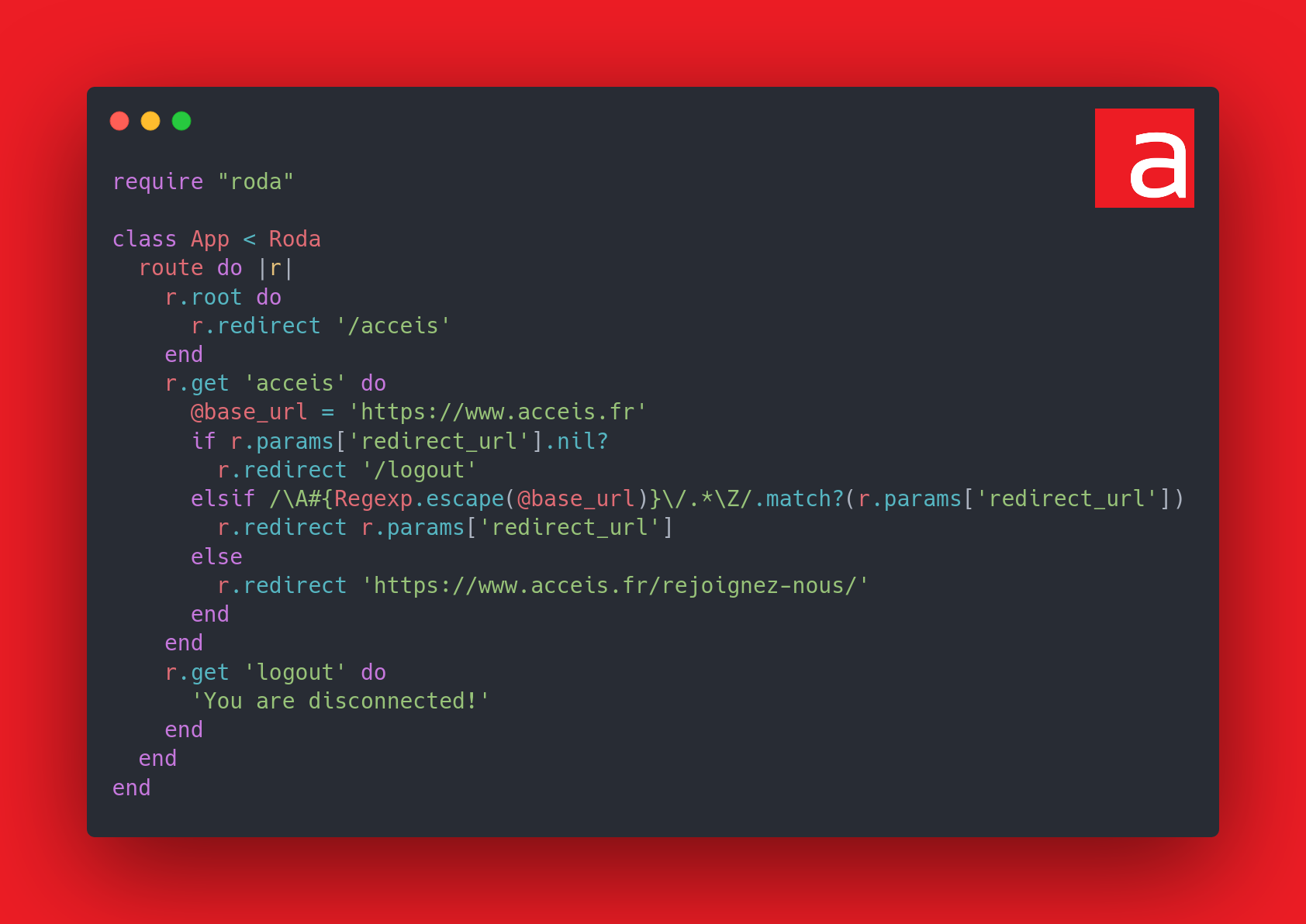
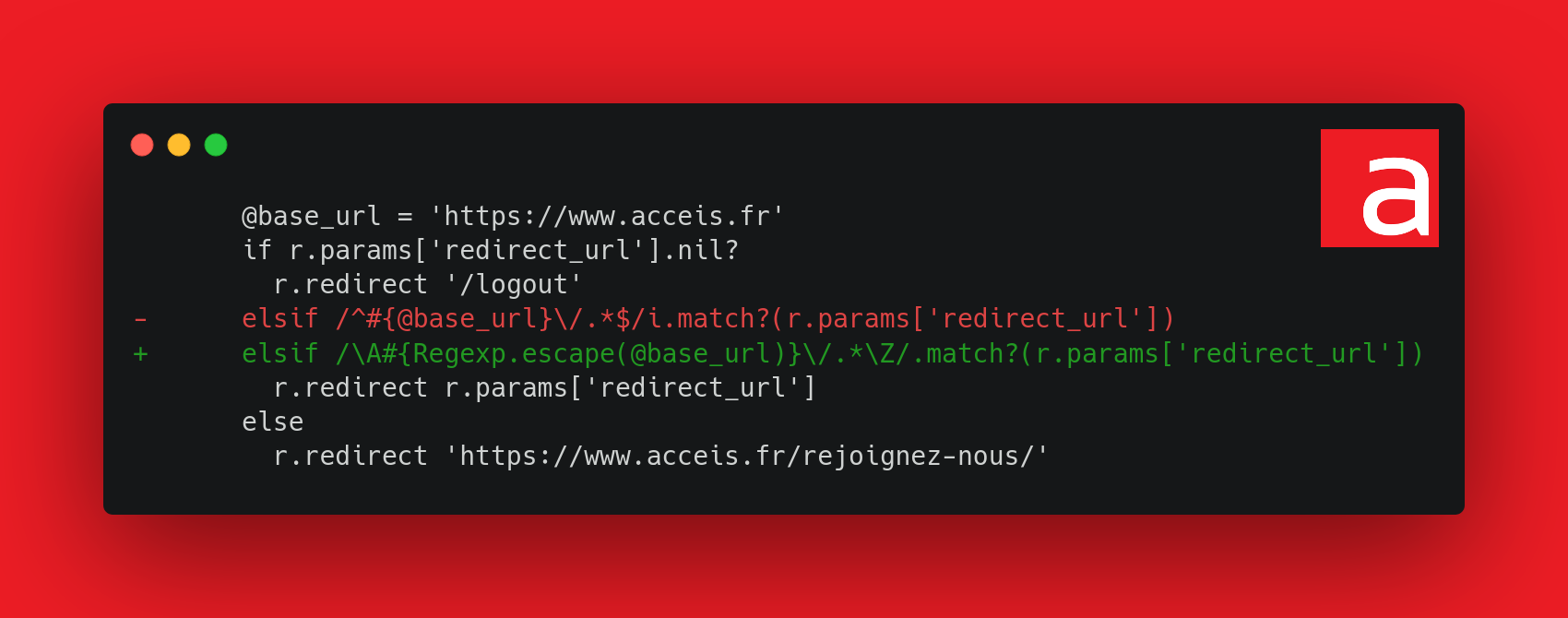
Therefore, the following elements have been modified:
- Use of
Regexp.escape()to escape regular expression operators - Replaced
^and$with\Aand\Zto ignore line feeds - Removed case-insensitive mode to avoid canonization
The source code is available on the Github repository Acceis/vulnerable-code-snippets.
About the author
Article written by Alexandre ZANNI aka noraj, Penetration Testing Engineer at ACCEIS.