

Connaissez-vous l’eBPF ? Son utilité ou son fonctionnement ?
Aujourd’hui, j’essaie pour vous d’esquisser une ébauche succincte de ce qui est, pour moi, une technologie révolutionnaire et très prometteuse pour le futur de l’informatique.
eBPF est une technologie révolutionnaire issue du noyau Linux qui peut exécuter des programmes dans un environnement confiné, mais avec les privilèges du noyau du système d’exploitation. eBPF est utilisé pour étendre de façon sûre et efficace les capacités du noyau, sans qu’il soit nécessaire de modifier le code source du noyau ou de charger des modules.
(extrait du site officiel dédié à l’eBPF)
Note : Cet article est aussi disponible en anglais 🇬🇧.
A l’heure ou cet article est écrit (janvier 2024), l’eBPF est utilisable sur tous les systèmes linux (version >= 4.16) et en cours de développement sur le noyau windows.
L’eBPF permet de reprogrammer le comportement du noyau sans compromettre sa sécurité.
Katran est un load balancer qui utilise la technologie eBPF pour filtrer les paquets directement dans le noyau et permet d’eviter un sur-traitement pour augmenter la performance.
Tetragon est un outil permettant de surveiller et sécuriser un cluster kubernetes et utilise également l’eBPF pour suivre l’activité des pods et remonter des alertes si le noyau exécute des tâches suspectes.
Cet article s’inscrit comme le premier d’une série d’articles dédiés à l’eBPF sur le blog d’ACCEIS.
Pour rester cohérent avec le jargon technique, le terme "noyau" ainsi que d’autres mots seront remplacés par leurs correspondances anglophone.
Objectif
L’objectif de cet article est d’arborer les concepts majeurs de cette technologie pour vous donner des clés de compréhension sur ses tenants et aboutissants, et peut-être vous donner envie d’en apprendre davantage … ?
Définition
L’eBPF est une technologie permettant de "se brancher" (hooker) à un comportement du kernel. Il peut s’agir d’un appel système (syscall) ou d’un événement réseau comme l’arrivée d’un paquet par exemple, ou directement une fonction précise du kernel. Ces points d’attache appelées "hooks" sont multiples et permettent d’intervenir avant ou après l’exécution d’une action du kernel.
Le processus de compilation et d’exécution d’un programme eBPF se fait en plusieurs étapes et cela mériterait un article complet dédié, mais nous nous attacherons seulement à des définitions générales.
Il est tout de même important de noter que l’exécution d’un programme eBPF se fait dans un environnement restreint pour la sécurité du kernel, mais peut transmettre de la donnée dans l’espace utilisateur (user space) en utilisant des maps eBPF.
Le schéma ci-dessous représente l’intégralité des concepts phares de l’eBPF qui seront abordés dans cet article. Il représente un programme eBPF (représenté par l’abeille) compilé puis chargé dans le noyau (kernel space) ainsi que la façon dont il récupère la donnée et l’envoie dans l’espace utilisateur (user space)
La différence entre l’espace utilisateur et l’espace noyau réside dans leur utilité. L’objectif du noyau et de fournir une couche d’abstraction sur l’intégralité du hardware d’une machine grâce à une API (syscall). L’espace utilisateur quant à lui utilise ces syscalls pour intéragir avec l’utilisateur final grâce à une interface, c’est le rôle de n’importe quel distribution linux par exemple.
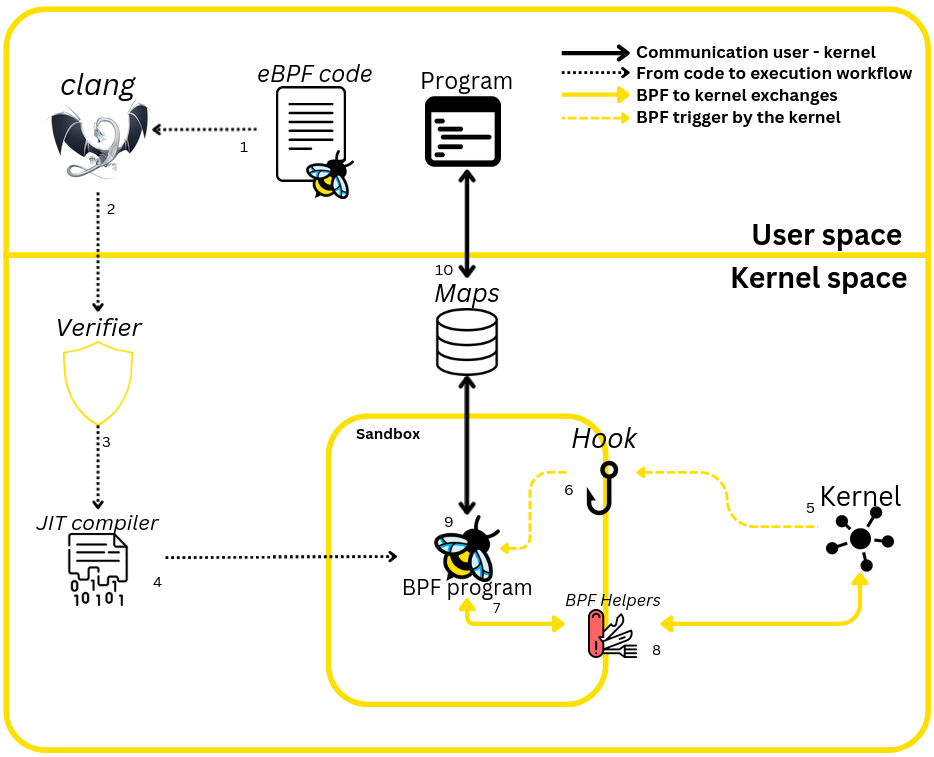
Ci-dessus le schéma du fonctionnement d’un programme eBPF : Initialisation du programme (1 à 4 sur la figure), le déclenchement (5 et 6) et les discussions avec le kernel (7 et 8), jusqu’aux communications entre le kernel space et user space (9 et 10)
Voici un exemple d’un programme eBPF hook sur le syscall sys_enter_execve. Vous remarquerez qu’un programme eBPF n’est autre qu’une seule fonction.
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
SEC("tp/syscalls/sys_enter_execve")
int acceis_hello_world(void *ctx) {
bpf_printk("Bonjour d'Acceis !");
return 0;
}
char LICENSE[] SEC("license") = "Dual BSD/GPL";L’initialisation du programme (de 1 à 4)
Pour démarrer un programme eBPF, il faut passer par 2 étapes importantes. Contrairement à un programme standard, la compilation seule ne permet d’exécuter le programme directement. Il doit d’abord être chargé dans le kernel, et c’est lui qui s’occupera de l’exécuter au moment venu.
Pour compiler le code, il faut utiliser clang pour qu’il soit transformé en bytecode eBPF.
clangest un compilateur pour LLVM
Une fois le bytecode obtenu, il est prêt à être envoyé au Verifier qui s’assure que le programme ne compromettra pas le comportement normal du kernel en respectant quelques règles.
En voici quelques-unes :
- Les boucles doivent être de taille fixe
- Une stack frame limitée à 512 octets
- 1 million d’instructions maximum (le verifier boucle dans le programme pour analyser la logique et ne doit pas dépasser 1 million d’instructions analysées)
Après s’être acquitté de sa validité auprès du verifier, le programme est chargé dans le kernel et est compilé grâce au Just In Time (JIT) Compiler qui transpose le bytecode en code machine après avoir effectué diverses optimisations.
Le programme est alors chargé dans une sandbox et n’attends plus qu’à être hook pour s’exécuter.
Le déclenchement du programme (5 et 6)
Lorsque le hook est déclenché, le kernel passe à notre fonction un context (ctx dans le code plus haut) qui contient un certain nombre d’informations. En fonction du hook choisi, son contexte diffère, mais pour le cas des syscalls ou des probes kernels celui-ci contient les paramètres des fonctions. Par exemple, si le syscall execve est utilisé, le contexte contiendra des données telles que le nom du fichier (ex : /usr/bin/ls) à exécuter et la liste des arguments passée à la commande.
Ceux-ci peuvent alors être modifiés à la volée par notre programme, et rendu ensuite au kernel pour qu’il soit exécuté.
execveest le syscall responsable de l’exécution de commande sur les systèmes linux
Le fonctionnement du programme (7 et 8)
Étant sandboxé, le programme eBPF ne peut pas exécuter des appels réseaux ou système, mais seulement dialoguer avec le kernel via une API intégrée au kernel qui met à disposition des fonctions appelées helpers. Ces fonctions s’occupent de récupérer la donnée du kernel et de la transmettre à notre programme.
Vous trouverez ici la liste des helpers utilisables
Dans le cadre de notre programme présenté plus haut, la fonction bpf_printk est une macro proposée par l’API bpf/bpf_helpers.h> et est l’équivalent d’un printf en C.
La communication user space – kernel space (9 et 10)
Pour transmettre de la donnée à un programme dit "standard" (qui n’est pas exécuté dans le contexte du kernel), le kernel possède des maps qui ont pour rôle de stocker la donnée. Celles-ci nous permettent d’ajouter, lire et supprimer la donnée de la mémoire.
bpf_map_lookup_elem(),bpf_map_update_elem(),bpf_map_delete_elem(), sont les 3 helpers responsable de la manipulation des maps
Un programme dans le user space peut alors utiliser ces maps via la libbpf de la même façon qu’un programme eBPF.
Et pour la suite … ?
Vous pourrez retrouver sur le blog la semaine prochaine un nouvel article sur l’eBPF en abordant un fonctionnement précis du kernel linux.
Voici un petit avant-goût du titre : Création d’un programme eBPF par la pratique – Dissimulation d’un PID (Partie 1)
Glossaire
Verifier
Outil mis en place directement dans le kernel et permettant de s’assurer qu’un programme est "sain" pour le kernel, c’est-à-dire qu’il n’endiguera pas son fonctionnement. Plusieurs règles sont à respecter, par exemple une stack frame de 512 octets, des restrictions sur les boucles.
Hooks
"Point d’ancrage" d’une fonction du kernel. Cela peut être un syscall, un comportement sur les cgroups, un événement réseau ou une fonction précise du kernel.
Exemple de point d’attache possible :
- Kprobe / Kretprobe / Uprobe / Uretprobe
- Tracepoint
- Traffic control (TC)
- Cgroup
- XDP
La liste complète sur le dépôt de BCC
Helpers
Fonctions permettant d’interagir avec le kernel et les maps.
Maps
Structure de données permettant de stocker et retrouver de la donnée. Une grande quantité de structure de donnée sont possibles, vous retrouverez la liste sur la documentation officielle dédiée
Pour aller plus loin
- L’histoire de l’eBPF
- Excellent livre pour apprendre
- 2 labs d’apprentissages très ludiques
- Tutoriels d’apprentissage de l’eBPF
- Un super blog pour aller plus loin
- Liste des gros projets qui utilisent eBPF
À propos de l’auteur
Article écrit par Tristan d’Audibert alias Sathi, apprenti ingénieur en cybersecurité chez ACCEIS.