
Un peu de contexte
Un audit de sécurité appelé Redteam consiste à mettre en œuvre une attaque informatique telle qu’elle pourrait l’être si elle était réalisée par des attaquants motivés à causer du tort à l’organisation ciblée. Bien que réalisé dans un contexte légal, sans objectif de nuire réellement, un audit redteam se veut le plus proche possible de la réalité à travers la simulation d’une attaque et laisse bien souvent le champ libre aux auditeurs quant aux techniques utilisées. Ainsi, toutes les techniques de social engineering et d’intrusion physique sont sérieusement prises en considération (spear phishing, copies de badges d’accès, dépôt de dispositifs malveillants dans les locaux, etc.). Contrairement aux tests d’intrusion classiques, dont le déroulé dépend des cibles à attaquer, les audits redteam sont dirigés par leurs objectifs. Les cibles ne seront en effet pas les mêmes si l’on souhaite réaliser un détournement de fonds ou si l’on préfère exfiltrer des documents stratégiques. Ce type d’audit a de plus l’avantage de pouvoir mesurer efficacement le niveau de maturité d’une organisation en matière de cybersécurité, tout en brossant large dans le périmètre audité (comprenant à la fois les composantes techniques, organisationnelles mais aussi humaines de la cible). Ils permettent enfin de mettre à l’épreuve les équipes dédiées à la détection et à la réaction aux incidents de sécurité.

Lors d’un audit redteam, une phase extrêmement importante est celle de la recherche d’informations blanches sur la cible visée (phase qualifiée d’OSINT pour OpenSource INTelligence). Lors de cette phase, les auditeurs recherchent toutes les informations publiquement accessibles leurs permettant de les aider à mieux comprendre leur cible. Dans ces informations se trouvent notamment la liste des collaborateurs de l’entreprise auditée, avec leurs emails et leur poste, ce qui peut permettre une attaque par spear phishing, mais aussi la liste de tous les éléments qui appartiennent à la cible et qui iraient gonfler la surface d’attaque de la cible.
Parmi les informations publiques dont des attaquants disposeraient se trouvent des listes de mots de passe ayant fuité de services tiers tels que Dropbox, Myspace, Linkedin ou encore Tumblr. Ces listes de mots de passe proviennent d’autres attaquants ayant piraté ces services et ayant récupéré, depuis leurs bases de données, la liste des comptes utilisateurs ainsi que leur mot de passe (ou en tout cas, le hash de leur mot de passe). Il suffit de se rendre sur le site haveIBeenPwned.com pour se rendre compte de la quantité de mots de passe ayant fuité sur internet.
Rechercher parmi ces fuites de données peut être particulièrement fastidieux et long en fonction de la quantité de données. Il est pourtant important de ne négliger aucun élément disponible dans ces données, car le moindre mot de passe valide peut être le point d’entrée à une attaque très efficace qui n’aurait pas lieu sinon.
Chercher des couples d’identifiants valides sur des applicatifs d’une cible à partir de mots de passe déjà utilisés auparavant par les mêmes personnes (sur d’autres services tiers) s’appelle le credential stuffing. Un couple identifiant/mot de passe fonctionnant sur un applicatif particulier est extrêmement intéressant pour des attaquants potentiels, car les applications protègent généralement mieux leur périmètre que leurs fonctionnalités internes. En quelques mots simples : il existe beaucoup plus de vulnérabilités applicatives nécessitant une authentification préalable que de vulnérabilités n’en nécessitant pas.
Par exemple, lors d’un audit redteam réalisé par ACCEIS, nous avons pu identifier un couple valide login/mot de passe d’un directeur des affaires financières de l’entreprise que nous attaquions (un seul couple login/mot de passe fonctionnant sur une trentaine de comptes identifiés). Ces identifiants nous ont permis d’accéder à l’extranet de l’entreprise. Grâce à toutes les applications internes, nous avons pu extraire la liste exhaustive de tous les employés de l’entreprise (avec leur poste et leur département au sein de l’entreprise). Un serveur de fichiers étant disponible, nous y avons déposé un document Word malveillant recopiant un modèle que les employés ont l’habitude de recevoir régulièrement par mail. Grâce à cela, une campagne de spear phishing a été possible, avec un taux de succès proche des cent pour cent, donnant une dizaine de shells dans le domaine Windows de l’entreprise. Les attaques par credentials stuffing, si elles sont possibles et qu’elles aboutissent, peuvent avoir des conséquences dévastatrices (pour finir l’exemple, l’audit redteam en question s’est fini sur l’application interne de réalisation de virements bancaires, après avoir ajouté ACCEIS comme bénéficiaire autorisé).
Leak scraping for fun and profit
Suite à cet audit, j’ai décidé d’aller plus loin en développant un outil dédié à la recherche d’identifiants dans des bases fuitées (que l’on appellera des leaks). L’objectif est de partir des leaks déjà à disposition (200GB+ de fichiers texte) et de les indexer au sein d’une base de donnée que l’on puisse utiliser facilement pour obtenir, le plus rapidement possible, la liste des mots de passe ayant fuité que les employés d’une entreprise en particulier sont susceptibles d’utiliser.
Description des besoins
L’outil à développer doit remplir certaines fonctionnalités et respecter des conditions pour être pertinent.
- La fonctionnalité principale de l’outil est d’obtenir la liste des identifiants associés à un domaine précis. Par exemple, l’utilisateur entre le nom « microsoft.com » et obtient la liste des identifiants fuités de personnes disposant d’une adresse email en « @microsoft.com«
- Il doit être facile d’ajouter de nouvelles données (de nouveaux leaks) sans que cela soit une opération trop longue
- La vitesse de recherche dans la base est la statistique à maximiser et à prioriser (sauf si cela impacte trop d’autres fonctionnalités)
- L’espace de stockage utilisé par l’outil n’est pas jugé comme étant une ressource limitée. L’outil va en effet créer des index en base et gérer un volume de données plus important que ce que représentent les leaks eux-mêmes. A choisir entre la vitesse d’exécution et l’espace de stockage, nous préfèrerons la rapidité d’exécution (un disque SSD d’un téraoctet ne coûte plus qu’aux alentours de 250€).

Uniformisation des leaks
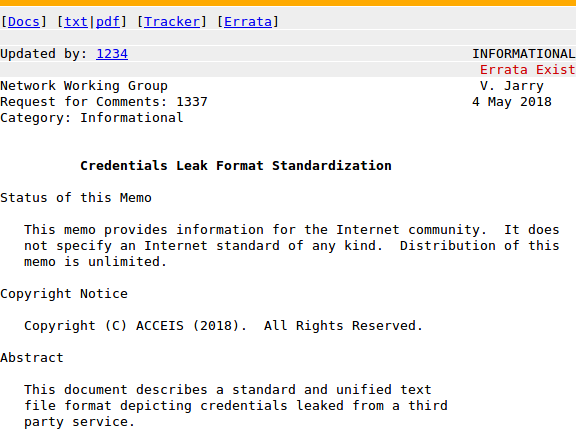
Un premier problème qui se pose quand on souhaite travailler sur nos leaks est la diversité des formats qui sont utilisés. Chaque leak présente ses données sous une forme différente, et contient toujours des entrées inutilisables. En effet, les leaks contiennent énormément de lignes sans mot de passe, sans email, ou alors avec un email modifié ne respectant pas le format que peut avoir un email. Des lignes sont parfois obfusquées, d’autres ne respectent pas le format utilisé dans le reste du fichier… Si l’on souhaite intégrer toutes les données exploitables dans une base unique, il va falloir nettoyer tout ça ! Un point très important malgré tout est que nous ne souhaitons pas perdre la moindre information des leaks initiaux, même si elles paraissent inexploitables. Il nous faut donc un premier outil capable d’extraire les informations jugées pertinentes d’un leak et de les transcrire dans un format « universel ». Le format choisi est le suivant : « email:hash:plain« . L’email est une donnée indispensable, contrairement au hash et au plain (mot de passe en clair), l’un des deux est suffisant pour rendre la ligne pertinente.
L’outil d’uniformisation des leaks ne peut en revanche deviner lui-même le format que le leak utilise initialement. Il faut donc demander à l’utilisateur de décrire une ligne typique du fichier initial. Pour faire cela, il est par exemple possible de demander à l’utilisateur une expression rationnelle, puis, pour chaque ligne du fichier initial, vérifier si cette ligne respecte ce format. Les lignes validées peuvent être enregistrées dans un fichier, les autres dans un second pour être examinées plus tard. Ainsi, si plusieurs formats cohabitent au sein du même leak, il est possible d’extraire chacun d’eux les uns après les autres jusqu’à obtenir un fichier propre et respectant un format unifié.
Pour décrire une ligne d’un leak lors de son nettoyage, l’utilisateur devra préciser où se trouvent l’email, le hash et/ou le plain. Cela peut se faire à travers des groupes capturants nommés, fonctionnalité nativement disponible lorsqu’on utilise des expressions rationnelles.
Prenons un exemple : l’utilisateur dispose d’un fichier CSV contenant les colonnes suivantes :
id,timep,email,status,gender,country,username,birthday,password
L’utilisateur pourra fournir l’expression rationnelle suivante :
(?:.+?,){2}(?P<email>.+?),(?:.+?,){5}(?P<plain>.*)
Cela aura pour effet de matcher toutes les lignes respectant le format csv identifié, tout en extrayant l’email et le mot de passe de chaque ligne à travers les groupes capturants nommés email et plain. Le résultat à tout cela est un outil dédié à l’uniformisation de leaks fonctionnel et efficace.
Quelques éléments techniques sur cet outil :
Il travaille sur place en mémoire, pour éviter de saturer la RAM de la machine qui s’en sert, même si le fichier à nettoyer est plus lourd que la quantité de mémoire allouable. Les IO disque étant ce qu’il y a de plus lent dans l’exécution du programme, les lignes du leak initial sont lues par blocs de 4096 (peut être spécifié comme argument au programme). Le programme pourrait être multi-threadé (option nbThreads) mais cela a peu d’intérêt pour les mêmes raisons (IO intensif). Un affichage en temps réel est disponible, présentant un certain nombre de statistiques sur le travail en cours : nombre de lignes déjà analysées, nombre de lignes considérées comme valides (matching), nombre de lignes valides donnant lieu à un couple login/mot de passe, nombre de lignes sans mail valide (ou sans mail tout court) et nombre de lignes présentant des caractères avec lesquels nous ne pouvons travailler (non utf-8). Avoir ces statistiques au runtime m’a paru important, au moins pour connaître l’avancement de l’analyse du fichier. Ces statistiques ne viennent pas ralentir le processus d’analyse du fichier, elles sont calculées et affichées via à un thread dédié.
Performances : 350 000 lignes / seconde (matériel : Linux 4.13, Cpu i5 @ 2.50Ghz x4, le leak étant stocké sur un SSD).
Référencement des leaks et de leur contenu
Nous souhaitons maintenant aller plus loin que de simples fichiers texte, en intégrant toutes ces données dans une base de données qui aura l’avantage de pouvoir accélérer les recherches. En soi, la recherche dans des fichiers est déjà possible, cela s’est notamment déjà vu avec l’archive Breach Compilation. Cette archive, trouvée sur un service caché fin 2017 a la particularité d’implémenter un index en forme d’arbre à deux niveaux sur les adresses mail des personnes présentes dans le leak. L’archive contient presque 2 000 fichiers servant à répartir les données. Si l’on recherche le mot de passe de l’utilisateur « em>toto@gmail.com« , il est possible de rechercher directement dans le fichier « breachCompilation/data/t/o« . Dans notre cas, nous voulons rechercher des données à partir du nom de domaine du mail. Si l’on souhaite utiliser un index sur celui-ci, il faut séparer le mail en deux parties : le prefixe et le domaine (un mail sera sous la forme prefix@domain). Comme on souhaite avoir un outil rapide et efficace, le mieux à faire reste de structurer les données de la façon la plus simple possible. La solution étudiée est la suivante :

Le préfixe, partie gauche de l’email, ne nous servira pas particulièrement, notre cas d’usage n’étant pas la recherche d’un utilisateur en particulier. Le domaine en revanche est l’information sur laquelle nous allons effectuer nos recherches. Nous aurons donc un index à créer. Le choix du type d’index est rapide : dans tous les SGBD nous avons globalement la possibilité de faire des index par Hashmaps ou des index en arbres (B-Tree). Les index en arbres ont la particularité de permettre des recherches par intervalles, ce dont nous n’avons pas besoin, de plus, la recherche d’une donnée parmi un tel index nécessite le parcours de l’arbre en question. Un index par hashmap quant à lui, se contente de mapper directement un hash à un ensemble de valeurs. Un index par hashmap nous permettra donc d’accéder très rapidement à l’ensemble des credentials associés à un domaine en question. A côté de ces données, on stockera des informations sur les leaks intégrés à notre base, uniquement pour suivre son évolution et être capable de situer la quantité de données présente. Les leaks auront le format suivant : nom, nombre de credentials, nom du fichier initial.
Dans le cadre de mes tests, j’ai pu expérimenter deux SGBD : MySQL et MongoDB. Dans le cas de mysql, nous aurons donc une table credentials et une table leaks. Dans le cas de mongodb, nous aurons deux collections. Tous les mécanismes sous-jacents restent très similaires tant que l’on garde un oeil haut niveau sur ce que l’on fait à partir de ce moment.
Insertion des données
Un problème qui se pose quand on travaille avec des milliards de lignes de données est leur insertion en base. Optimiser l’insertion d’un gros volume de données dans des bases mysql et mongodb devient primordial si l’on ne souhaite pas avoir un outil prenant des semaines de travail à chaque nouveau leak que l’on souhaite intégrer.
Un autre problème que pose l’insertion des données est celui du traitement des doublons. En effet, si l’on souhaite éviter les doublons dans notre base de données, cela implique que pour insérer un credential, il faut scanner toute la base pour vérifier qu’il n’y est pas déjà. Cela implique donc des coûts de traitement et donc de temps. Le schéma suivant présente la vitesse à laquelle on peut insérer des données dans une base mysql, en fonction du nombre d’insertions déjà réalisées.
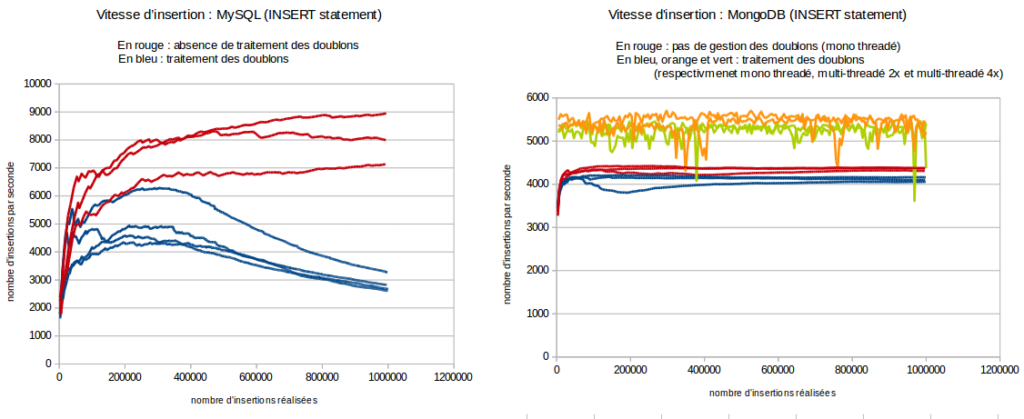
Les lignes de même couleur sur un graphique représentent différents échantillons réalisés avec la même technique. Sans surprise, la vitesse d’insertion chute drastiquement lorsque l’on traite les doublons avec MySQL, ce que l’on ne constate pas avec mongodb (étonnamment). Les mesures sont faites pour un million d’insertions, on peut supposer que mongodb résiste mieux que MySQL à ce genre de traitement (tout en étant malgré cela deux fois plus lent que MySQL sur l’insertion). Ce que l’on constate en revanche chez les deux SGBD, c’est la faible vitesse d’insertion ! Nous n’insérons que 9.000 lignes par seconde chez MySQL contre 4/5.000 chez Mongodb (on peut considérer les statistiques légèrement biaisées pour mongodb, je n’ai pas regardé la vitesse d’insertion multi-threadée sans gestion des doublons). Cela nous amène donc à la recherche de méthodes plus efficaces pour insérer des données en grand volume dans nos base.
Mysql et Mongodb possèdent tous les deux leur propre méthode d’insertion de grands volumes de données. Pour MySQL, nous pouvons nous servir de la directive LOAD DATA FROM FILE, qui nous permet de traiter un fichier CSV présent sur le disque et de l’importer. Un problème que nous avons avec MySQL pour réaliser des statistiques reste l’absence de compteur global de lignes dans une table. Nous pouvons maglré tout utiliser l’attribut ROW_COUNT de la table INFORMATION_SCHEMA.TABLES qui contient une approximation du nombre de lignes (basée sur le poids de la table et du poids moyen d’une entrée dans celle-ci).
Mongodb quant à lui dispose d’un utilitaire dédié, mongoimport servant à importer des données depuis des fichiers texte sous différents formats (JSON, CSV, TSV …). Mongodb retient dans les statistiques des collections le nombre exact de documents présents, ce qui nous sera utile pour réaliser nos statistiques. En utilisant ces deux directives, nous obtenons les résultats suivants (il devient utile de comparer les échelles du graphique avec celles des précédents) :
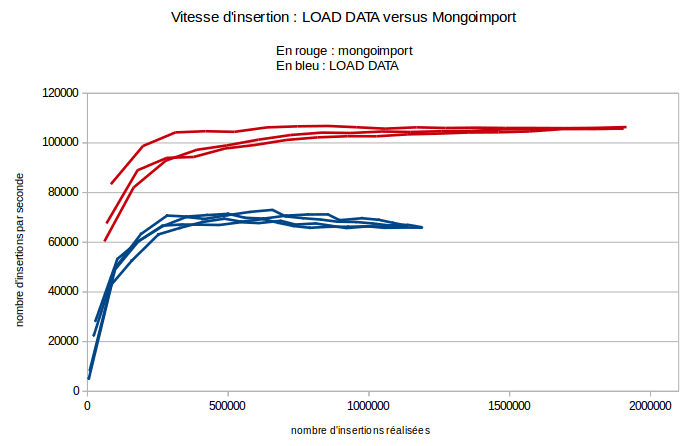
Le principal élément qui nous intéresse ici est le changement d’échelle : ces méthodes sont deux fois plus rapides que de naïfs insert dans une boucle. Les éléments importants à savoir sur LOAD DATA et mongoimport sont les suivants :
- InnoDB utilise un lock global sur les tables lors de l’insertion. Cela implique que multi-threader ne servira à rien
- MongoDB en revanche supporte très bien les insertions concurrentes, les résultats de mongoimport présentés dans le graphe ci-contre sont réalisés avec 8 threads concurrents
- Les deux méthodes travaillent sur des formats de fichiers spécifiques. Nous avons utilisé ici du CSV. Cela implique qu’il faut avant tout parser nos leaks (déjà standardizés) pour les passer en CSV, ce qui ajoute un temps de traitement non négligeable (mais faible et linéaire).
- On peut accélérer encore un peu mongoimport en démarrant notre serveur mongodb sans journaling (journaling : false dans /etc/mongod.conf sous linux).
Poids des données
Une statistique importante à prendre en compte est aussi le poids des données, et surtout, l’overhead généré par les SGBD et les index. Comme tout le boulot d’optimiser les insertions a été réalisé, nous pouvons commencer à travailler avec un important volume de données. Pour les tests suivants, 1 832 214 735 credentials ont été chargés (un milliard huit cent million). A noter : un champ a été ajouté à la table contenant les credentials. Ce champ sert à relier un leak à ses credentials, avec l’index qui va avec. Chaque credential à donc le champ leak contenant un entier représentant l’identifiant du leak qui lui est associé (clef étrangère). Nous avons donc deux index : leak_index servant à obtenir rapidement les credentials associés à un leak, et domain_index servant à obtenir rapidement les credentials associés à un domaine particulier.
Premier élément de statistiques : la base MySQL pèse 196,71 Go, la base MongoDB pèse 158,62 Go. MongoDB gère donc mieux le stockage que MySQL pour notre cas d’usage, et de beaucoup : il est 20% plus efficace ! On peut ensuite regarder la répartition du poids des données au sein de nos tables et collections grâce au graphique suivant.
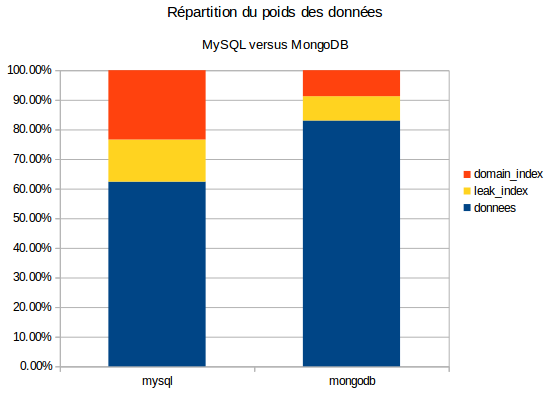
Il est à noter aussi que l’index leak_index n’est pas indispensable et n’a seulement servi que pendant les tests, ceux-ci demandant énormément d’insertions et de suppressions successives de leaks en particulier (des jeux de données plus que des leaks).
On remarque que mongodb maîtrise mieux le poids de ses index que MySQL. On y retrouve complètement notre gain de 20%.
Après avoir réalisé toutes ces mesures, j’ai donc développé un outil pour importer le plus vite possible des leaks standardisés dans une base mongo ou mysql. L’outil parse le leak standardisé et le transforme en CSV temporairement, puis importe le CSV dans l’un ou l’autre des SGBD. Ici encore, les erreurs pouvant survenir sont loggées dans un fichier séparé pour garder une trace de toute donnée ayant posé problème à un moment ou un autre. Cette opération d’import pouvant être longue, j’ai rajouté un feedback visuel de l’état d’avancement des opérations (cela m’a pris quelques heures d’importer les 1.400.000.000 de lignes présentes dans l’archive BreachCompilation dont j’ai parlé un peu plus haut).
Accès aux données
Tout cela est bien beau, mais il reste encore à mettre en oeuvre la partie la plus importante du projet : la recherche parmi cet ensemble de données. Comme nous avons déjà mis les index qui vont bien dans notre base, cela ne devrait pas poser de problème. J’ai développé un petit outil proposant une interface web pour rechercher dans nos données.
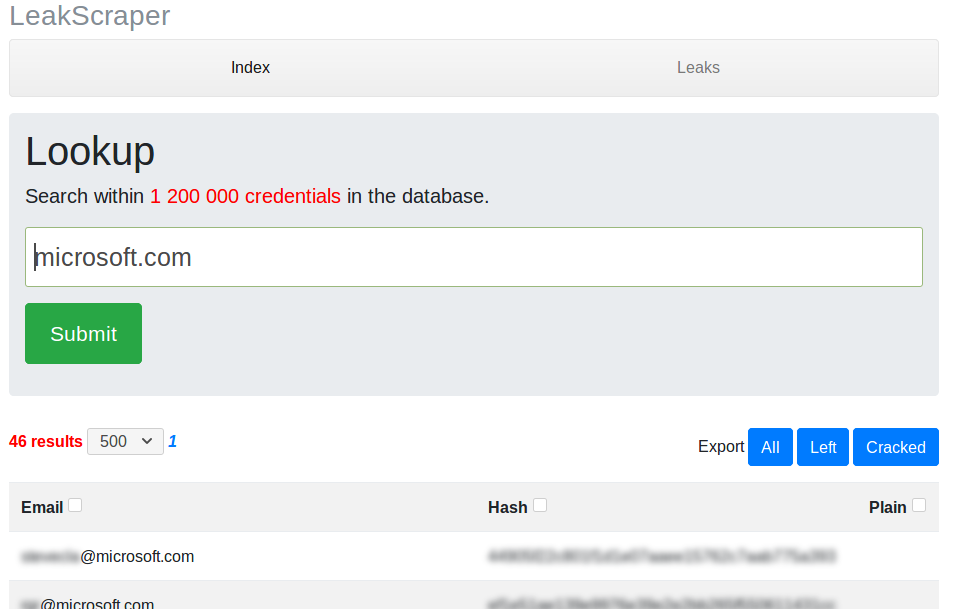
L’outil (savamment nommé LeakScraper) permet de rechercher efficacement (en temps et en mémoire) parmi nos quelques milliards d’enregistrements. Il permet au passage de télécharger rapidement les credentials qui nous intéressent (tous ou bien juste ceux que nous n’avons pas déjà cassés). Les résultats sont paginés, en étant affichés par défaut cinq-cents par cinq-cents. Un dernier problème se posant au niveau de la recherche est présent lorsque l’on souhaite compter le nombre de résultats de notre requête. Si par exemple je souhaite voir les credentials des comptes en gmail.com, il est nécessaire de parcourir la base à la recherche des lignes correspondantes. Malgré les index, cela peut être extrêmement long. J’ai donc fait le choix de perdre en fonctionnalité contre un gain très important en performance : le nombre de résultats de notre recherche ne s’affiche que lorsqu’il est inférieur à une limite fixe. Au-delà de cette limite, le compteur indiquera « plus de n resultats ». Ce choix implique un effet secondaire : il n’est plus possible de savoir à l’avance combien de pages de cinq-cents credentials il existe (cette information s’obtenant grâce au nombre de résultats).
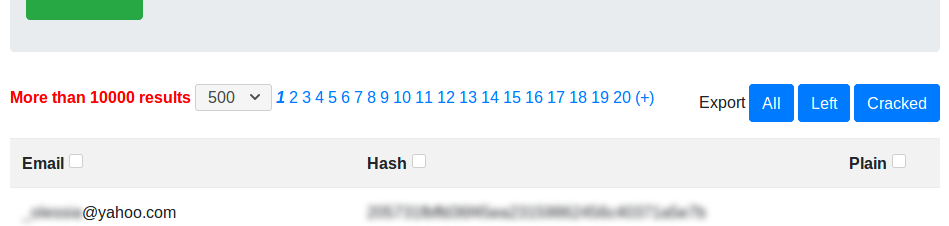
J’ai donc paginé le système de pagination. Tant que nous avons moins de vingt pages de credentials à compter (10.000 résultats ou moins), tout se passe correctement, le nombre de credentials trouvés est affiché correctement, nous pouvons naviguer au sein des pages de résultats facilement. Au-delà de cette limite (le compteur de résultats indique alors « plus de 10.000 résultats »), nous pouvons navigueur parmi les vingt prochaines pages de résultats via un bouton « + ». Cela permet de ne jamais travailler qu’avec 10.000 résultats maximum à un instant T. En revanche, plus l’on avance dans les blocs de vingt pages (disons que l’on clique sur ce bouton « + » dix fois par exemple), plus les temps de chargement sont long (nécessité de compter le nombre de résultats de plus en plus précisément). En revanche, le compteur du nombre de résultats devient de plus en plus précis, jusqu’à atteindre la valeur exacte, lorsque l’on atteint le dernier bloc de pages de résultats.
Ce choix (légère perte en fonctionnalité pour gain conséquent en performance) est pris assez simplement : nous n’allons jamais obtenir plus de 10.000 résultats dans le cadre d’une utilisation « classique » de l’outil. Ayant pour objectif de servir pour de l’OSINT en audit Redteam, il serait étonnant d’avoir autant de résultats liés à une entreprise spécifique (outre les fournisseurs de mails tels que gmail et consort).
En mesurant le temps de réponse de l’application au niveau des appels à la base de données, nous pouvons sortir deux indicateurs : le temps que l’application prend pour accéder aux données ainsi que le temps qu’elle prend pour compter le nombre de résultats de notre recherche.
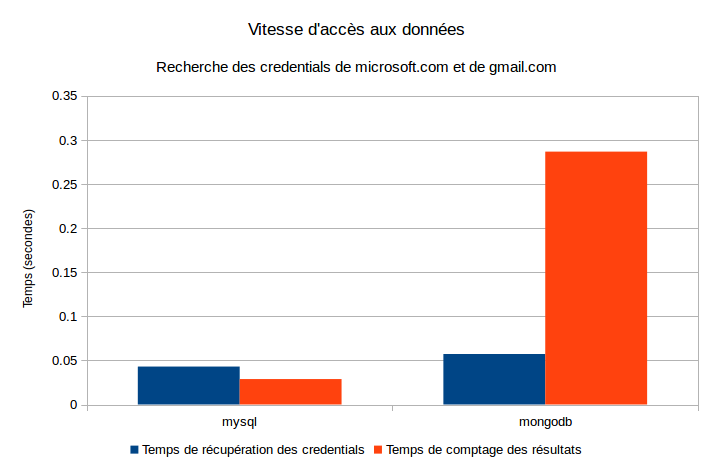
On constate que MySQL est globalement plus performant sur le graphique ci-joint. Les données ont été obtenues en recherchant les credentials associés aux domaines gmail.com (recherche très lourde, la moitié des comptes leakés sur internet étant chez gmail) et microsoft.com (moins de 10.000 résultats, recherche plus rapide). Les statistiques sont donc légèrement biaisées à la hausse (étude d’un cas inconfortable pour l’application). Le volume de données présent lors des mesures est le même que lors du calcul du poids de la base : 1 832 214 735 credentials.
MongoDB est moins bon, particulièrement à compter le nombre de résultats. On peut supposer que ses index sont moins efficaces que ceux de MySQL. Cette supposition est renforcée par nos derniers tests : les index de mongodb sont deux fois et demi plus légers que ceux de MySQL ! MongoDB est beaucoup plus sensible à ce dont il dispose en mémoire. Il a notamment besoin d’avoir assez d’espace disponible pour y mettre son working set et est beaucoup plus performant lorsque les index sont entièrement contenus en mémoire. Dans notre cas, l’index qu’il serait intéressant d’avoir en mémoire fait plus de 12 Go, ce qui serait possible avec une machine plus puissante.
Pour conclure
Tout le travail réalisé permet de partir sur de bonnes bases en matière de fouille dans un grand volume de données pouvant servir en audit. Il est important de rappeler que tout le travail a été fait sur un laptop, il n’est pas encore nécessaire de disposer d’une machine très puissante. Les axes d’amélioration portent sur plusieurs points :
- Disposer d’un outil capable de nettoyer la base de ses doublons, petit à petit, sans épuiser la mémoire de la machine
- Disposer d’un moyen permettant de mettre à jour des entrées dont les hashes auraient pu être cassés (ajouter le plain qui viendrait à manquer sur certaines entrées).
Tous les outils développés sont disponibles sur la page github d’ACCEIS : leakScraper. Ce dépôt ne possède pas de branche master (oui, c’est possible), mais deux branches distinctes : une pour MongoDB et une pour MySQL. Libre à vous de choisir ce qui vous arrange au vu des tests réalisés et présentés dans cet article (bien que la branche par défaut soit celle de MongoDB).